一、基础概念
Java 发展里程碑
- 1995年,Sun公司的James Gosling开发了Oak,由于商标问题改名为Java并发布
- 1996年发布JDK 1.0,包含运行环境JRE和开发环境JDK。JRE包含核心API,JVM等,开发环境包含编译器(javac等compiler命令)、调试器jdb等
- 1997年发布JDK 1.1,添加JIT即时编译器,将常用指令保存到内存,下次调用不需要重新编译
- 1998年发布JDK 1.2,添加JSP/Servlet、EJB等规范,并将Java分成J2SE、J2EE和J2ME,后续对应Java SE(标准、桌面端),Java EE(企业、服务器端),Java ME(嵌入、移动端)
- 2002年发布JDK 1.4,期间在企业应用涌现出大量开源框架,Struts、Hibernate、Spring等。企业应用服务器WebLogic、WebSphere、JBoss等
- 2004年发布JDK 1.5,增加了泛型、注释、自动装箱拆箱等
- 2006年发布JDK 1.6,通过hadoop占领大数据领域
- 2007年Google推出Android,使用Dalvik虚拟机来运行dex文件,使用Java作为客户端编程语言
- 2009年Orcale收购了Sun
- 2011年发布Java SE 7,引入菱形语法、多异常捕捉、自动关闭资源的try等新特性
- 2014年发布Java SE 8(LTS),带来Lambda表达式、流式编程等特性,长期支持版本
- 2017年发布Java SE 9,模块化,轻量化,采用了更高效的G1垃圾回收器
- 2018年发布Java SE 11(LTS),长期支持版本,包含17个JEP(JDK Enhancement Proposals,JDK增强提案)
Java 运行机制
- java编写的程序,既是编译型的,又是解释型的。代码经过编译会生成与平台无关的字节码(class文件),由JVM对字节码进行解释和运行。编译只进行一次,而解释在每次程序运行时都会进行。
- 字节码不面向任何具体平台,只面向JVM,需要为不同的平台实现相应的虚拟机。
- Oracle制定了Java虚拟机规范,并且发布一个官方的JVM实现,定义了JVM的指令集、寄存器、类文件格式、栈、垃圾回收器、存储区等。
- 编译运行java程序,需要安装JDK,且配置Path环境变量后使javac和java命令生效。1.5版本后不需要设置classpath。
- JVM从类的main方法开始执行。
1 | $ javac -encoding UTF-8 -d . HelloWorld.java //javac -d DESTDIR SRCFILE |
Java优势
- 简单性
- 面向对象
- 可移植性,Write Once,Run Anywhere
- 高性能
- 分布式
- 动态性
- 多线程
- 安全性
- 健壮性
二、数据类型和基础类库
Java支持两种数据类型,基本类型和引用类型。
基本数据类型
包括数值型(整数、浮点)、字符型和布尔型。
| 基本数据类型 | 类别 | 字节数 | 说明 |
|---|---|---|---|
| byte | 整数 | 1 | -128到127 |
| short | 整数 | 2 | -32768到32767 |
| int | 整数 | 4 | -2^31到2^31-1 |
| long | 整数 | 8 | -2^63到2^63-1,添加L做后缀 |
| float | 浮点 | 4 | 1位符号 8位指数 23位尾数,尽量避免浮点比较 |
| double | 浮点 | 8 | 1位符号 11位指数 52位尾数 |
| char | 字符 | 2 | unicode编码,2字节(UCS-2)。通过代理项对扩充到4,用于增补字符,char是unsigned,而short是signed。Java以定长的UTF-16作为内存的字符存储格式 |
| boolean | 布尔 | - | 官方jvm里,单独使用被编译为int类型是4个字节,数组中是1个字节 |
包装类
java.lang包中的Byte、Short、Integer和Long类,将基本类型封装成一个类,都是Number的子类。
Java为8种基本类型提供面向对象的支持,定义了响应的引用类型,称之为基础数据类型的包装类。
| 包装类 | 对应基本数据类型 | 构造方法 |
|---|---|---|
| Integer | int | Integer(int number); Integer(String str); |
| Boolean | boolean | Boolean(boolean value);Boolean(String str); |
| Byte | byte | Byte(byte value); Byte(String str); |
| Character | char | Character(char value) |
| Double | double | Double(double value); Double(String str); |
| Short | short | Short(short value); Short(String str); |
| Long | long | Long(long value); Long(String str); |
| Float | float | Float(float value); Float(String str); |
包装类实现了基本数据类型、包装类和字符串的转换。JDK1.5以后提供自动装箱和自动拆箱功能,简化基本数据类型、包装类两者的转换。
- 把基本类型转换为包装类:包装类的valueOf()静态方法
- 把字符串转换为包装类:包装类valueOf(String s)静态方法
- 把包装类转换为基本类型:包装类的xxxValue()实例方法
- 把字符串转换为基本类型:包装类parseXxx(String s)静态方法(除Charater外)
字符串
1、字符集,是一个系统支持的所有抽象字符的集合。字符集就是一个映射关系,没有规定编码。对字符集进行编码的最直接的方式是为每个字符在给定的范围之内分配一个整数序号,这个整数序号被称为该字符的码点。
- ASCII 1个字节,是计算机的缺省字符集,包含英文所需要的全部字符。
- GB2312 中文字符集,ASCII部分用1个字节,剩余部分用双字节,有7000多个汉字。
- GBK 是GB2312的扩展,2个字节,包含20000多个汉字。例如,何对应的GBK字符集的十进制是47822,对应的16进制为BACE
- GB18030 是GBK字符集的超集,包含了中(多民族)、日、韩三国语言中的所有字符。
- Unicode,统一字符集,几乎包含了世界上所有需要的字符。Unicode中的码点被分为17个平面,每个平面中包含65536个字符。U+0000到U+FFFF称为BMP(Basic Multilingual Plane,基本多语言平面)。U+010000到U+10FFFF称为SP(Supplementary Planes,增补平面,有16个)。Unicode字符百科
2、字符编码,是字符集的字符和实际的存储值之间的转换关系。即需要传输或存储时,需要先将内存中的unicode进行字符编码。
- 为了解决Unicode的传输问题,出现了UTF(USC Transfer Format)标准,UTF-8就是每次8个位的传输数据,UTF-16就是每次16个位,UTF-32是每次传输32位。
- UTF-8编码变长,使用1-6字节存储。
- UTF-32编码固定长度,使用4字节存储,足够存储所有字符。
- UTF-16编码,定长为2字节或4字节。2字节的UCS-2在BMP平面,4字节的UCS-4在增补平面。Unicode中位于U+D800~U+DFFF之间的字符是特别为UTF-16编码预留的,没有收录任何字符。
- Java的char类型是用UTF-16编码的,码点在BMP平面上的65536个字符为2字节,在增补平面通过代理项对扩充到4字节。String内部使用char数字来存储,因此在JVM内部,读入到内存的字符和字符串都是采用的UTF-16编码。而在JVM之外,例如生成的字节码文件(.class)文件采用的是UTF-8编码。
目前Unicode码点对于范围[0x 000000 - 0x 10FFFF]是有定义的,因此UTF-8只可能映射到1-4个字节。大于该范围暂时是没有意义的,只是UTF-8的编码规则如此。
| Unicode字符集(16进制) | UTF-8编码(2进制) |
|---|---|
| 00 0000 - 00 007F | 0xxxxxxx |
| 00 0080 - 00 07FF | 110xxxxx 10xxxxxx |
| 00 0800 - 00 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 01 0000 - 10 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 20 0000 - 3FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 400 0000 -7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
例如“何”对应的unicode字符集的十进制20309,16进制表示为\u4f55,二进制100111101010101,在UTF-8编码中属于3字节,前面补0后编码成11100[100] 10[111101] 10[010101],即%E4%BD%95
| Unicode字符集(16进制) | UTF-16编码(2进制) |
|---|---|
| 00 0000 - 00 FFFF | xxxxxxxx xxxxxxxx |
| 01 0000 - 10 FFFF | 110110xx xxxxxxxx 110111xx xxxxxxxx |
增补平面内,高代理项(high-surrogate)范围0xD800-0xDBFF,低代理项(high-surrogate)范围0xDC00-0xDFFF,而该范围预留,可用来区分2字节和4字节。
例如“何”对应的unicode字符集的十进制20309,16进制表示为\u4f55,二进制1001111 01010101,在BMP中,UTF-16编码后为2字节,前面补0后编码成01001111 01010101,即%79%85
例如“🍓”(草莓字符)对应的unicode字符集的十进制127827,16进制表示为\u1f353,二进制0001 11110011 01010011,二进制需要减去初始值0x10000,变成0000111100 1101010011(分成2个10位,前面补0)。在增补平面,UTF-16编码后为4字节,即110110[0000111100] 110111[1101010011],即%D8%3C%DF%53
3、字节序,是针对多个字节的排序,当传输或者存储的字符编码超过1个字节,需要指定字节间的顺序。UTF-8的编码单元是1个字节,因此没有字节序,UTF-16(分为UTF-16LE和UTF-16BE,编码单元为2字节)和UTF-32(分为UTF-32LE和UTF-32BE,编码单元为4字节)有字节序。
举例来说,数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
- Big-Endian,大端序,将高位字节存储在最低地址。高位字节在前,低位字节在后,这是人类读写数值的方法。以0x2211存储,即0x22存储在0x100地址,0x11存储在0x101地址。JVM默认使用大端序。
- Little-Endian,小端序,将低位字节存储在最低地址。低位字节在前,高位字节在后。Intel和AMD的CPU中默认是Little-Endian。以0x1122存储,即0x11存储在0x100地址,0x22存储在0x101地址。Intel和AMD的cpu默认使用小端序,如notepad另存为选择编码,对于UTF-16,默认是小端,此外还有个Unicode Big Endian。
- BOM(Byte Order Mark),就是字节序标记。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。Java可以通过字符串的getBytes方法读取的字节数组,如是[-2,-1]开头,即BOM是FEFF代表UTF-16/32的大端序。如是[-1,-2],即BOM是FFFE代表UTF-16/32的小端序。UTF-8可以没有BOM,但如果添加了BOM则会有EF BB BF开头的字节流,就知道这是UTF-8编码。
| 序列 | 操作 | 方法 | 说明 |
|---|---|---|---|
| 1 | 连接字符串 | + | 字符串创建后,长度固定,内容不能被改变和变异。+操作会生成新的String实例,如需要频繁修改,会增加系统开销 |
| 2 | 长度 | str.length(); | |
| 3 | 字符串查找 | str.indexOf(substr); str.lastIndexOf(substr) | |
| 4 | 获取指定索引的字符 | str.charAt(6); | |
| 5 | 获取子字符串 | str.substring(int beginIndex); str.substring(int beginIndex,int endIndex); | |
| 6 | 去空格 | str.trim(); | |
| 7 | 字符串替换 | str.replace(char oldChar,char newChar); | |
| 8 | 字符串的开始与结尾 | str.startsWith(String prefix); str.endsWith(String suffix); | |
| 9 | 是否相等 | equals();equalsIgnoreCase() | “==”比较的是两个字符串的地址是否相同。 |
| 10 | 按字典顺序比较 | str.compareTo(String otherstr); | 如在参数之前为负整数,相等为0,之后为正整数 |
| 11 | 字母大小写转换 | str.toLowerCase(); str.toUpperCase(); | |
| 12 | 字符串分割 | str.split(String sign); str.split(String sign,int limit); | 可限定分割次数 |
| 13 | 字符串格式化 | str.format(String format,Object…args); | 可对日期、时间以及组合,各种进制(如%d为十进制)、其他类型进行格式化。 |
| 14 | 使用正则表达式 | str.matches(regex); | |
| 15 | StringBuilder类 | bf.append(content); bf.insert(int offset,arg); bf.delete(int start,int end); | 可变字符串,线程不安全,但效率高。 |
| 15 | StringBuffer类 | 同样是可变字符串,方法基本和StringBuilder差不多,且线程安全(方法都添加了synchronized关键字) |
1 | public class StringBasic { |
数组
1 | public class ArrayBasic { |
数学运算:Math类
三角函数、指数对数函数、取整函数、最值函数等。
1 | Math.PI; |
随机数
Math.random();随机数,0.0<=值产生<1.0
(int)(Math.Random()*n),是根据当前时间作为参数的伪随机数。
也可使用java.util.Random类来生成。
大数字运算:java.math.BigInteger类和java.math.BigDecimal类。
1 | BigInteger value=new BigInteger(String val); |
常用类库
| 常用类 | 说明 |
|---|---|
| Object | 基类 |
| Scanner | 键盘输入 |
| System | 标准输入输出 |
| Runtime | 运行环境 |
| Date | 日期 |
| Calendar | 日历 |
| Pattern | 正则表达式 |
| Matcher | 正则匹配 |
枚举常量
类型安全,运行效率高。使用enum关键字定义枚举类型。它被编译器编译为一个继承于Enum的类。
1 | // enum关键字,其实是继承Enum类 |
class编译完成后类似下面:
1 | final class SeasonEnum extends Enum { // 继承自Enum,标记为final class |
针对带私有构造方法的枚举类,可定义如下
1 | // 枚举类同样可以有成员变量、构造器和方法 |
class编译完成后类似下面:
1 | public final class WeekEnum extends Enum { // 继承自Enum,标记为final class |
- 枚举常用方法:values() 返回枚举成员的数组形式。valueOf将字符串转换为枚举实例,ordinal()得到枚举成员的位置索引。
- 枚举可用来实现单例,由于机制,使得成为单例的最佳实践。
- 还有EnumMap和EnumSet等类。
1 | public class EnumBasic { |
三、类和对象
类
从面向过程到面向对象,先抽离出对象,识别属性和行为。类就是封装属性和行为的载体,对象是类的一个实例。
类定义=成员变量(状态数据)+方法(行为)
面向过程中,一切以函数为中心,而面向对象中,一切以对象为中心。
1 | 吃(猪八戒,西瓜) //面向过程 |
1 | [修饰符] class 类名 |
对象
- 对象创建的根本途径是构造器,通过new关键字来调用某个类的构造器。Test test=new Test();
- 访问对象的属性和行为,使用“对象.类成员”来获取。
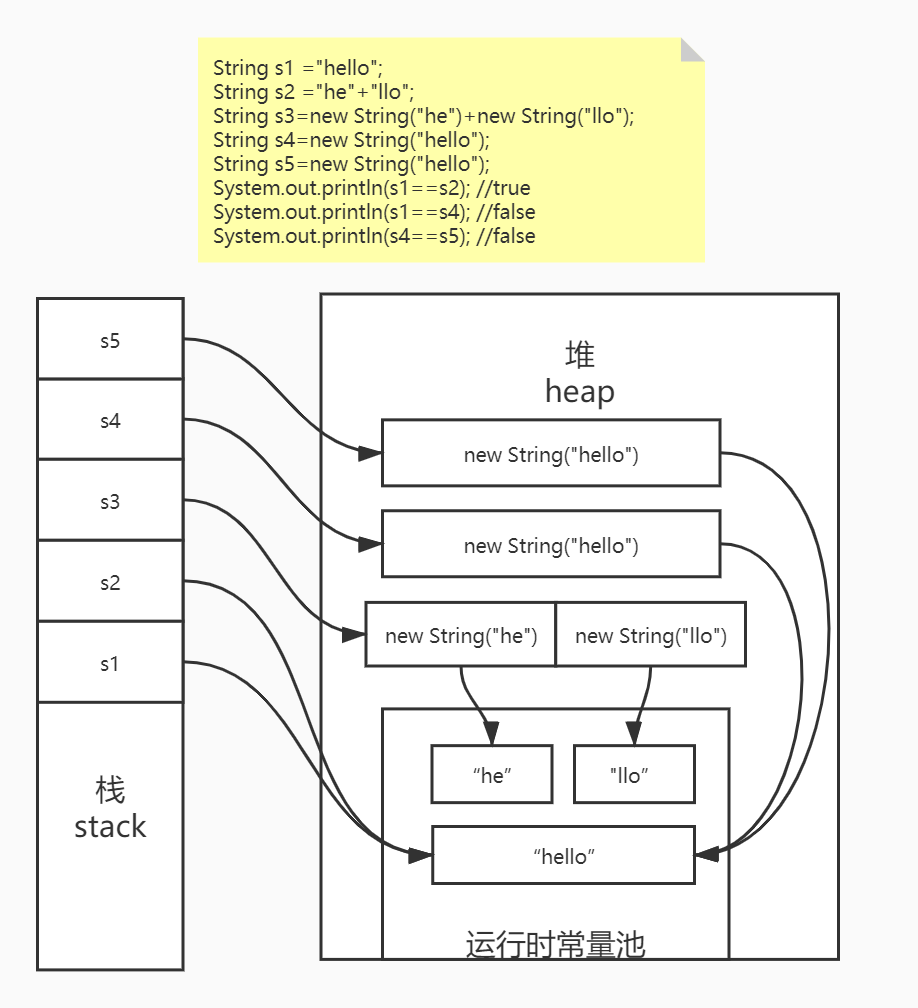
- 对象的成员变量数据实际存在在堆内存里,而引用变量只是指向该堆内存里的对象,引用变量存放在栈内存中。
- 对象的比较,使用 “==”运算符代表两个对象引用的地址是否相等。
- 对象的销毁,当对象引用超过作用范围,被会视为垃圾。将对象赋值为null。
- 针对垃圾回收机制,finalize()方法可能无效,可使用System.gc()来手动执行回收。
- this,总是指向调用该方法的对象,是本类对象的引用。使用场景有:在构造器中引用该构造器正在初始化的对象,和在方法中引用调用该方法的对象。Java允许对象的一个成员直接调用另一个成员,可以省略this前缀。
- java对象的复制,分为引用拷贝(用等号的直接赋值)和对象拷贝(分为浅拷贝和深拷贝)。浅拷贝仅仅复制所考虑的对象,而不复制对象引用的对象。在浅克隆中,当对象被复制时只复制它本身和其中包含的基本类型的成员变量,而引用类型的成员对象并没有复制(其中String、包装类等引用类型看起来像是复制了是因为他们是不可变类)。浅拷贝需要实现cloneable接口。深拷贝需要对对象的对象也进行浅拷贝。深拷贝也可通过实现Serializable接口序列化的方式。
变量
变量分为成员变量和局部变量。也可分为对象的引用变量和基础类型的变量。
1、成员变量分为静态变量和实例变量。
静态变量,也叫类变量,添加static关键字,能以“类名.类变量”的方式调用,也允许以“实例.类变量”的方式调用。
实例变量,只能以“实例.实例变量”的方式调用。
成员变量的初始化,当系统加载类或者创建该类实例时,会自动为成员变量分配内存空间,并指定初始值。以引用类型为例,栈内存为引用的变量,堆内存包含类变量(只创建一次)和实例变量(每次初始化均创建)。
2、局部变量分为形参、方法局部变量和代码块局部变量。与成员变量不同,局部变量除形参之外,都必须显式初始化,否则不可以访问它们。
局部变量的初始化,局部变量定义后,系统不会为局部变量执行初始化,并未分配内存,等到为变量赋初始值后才分配内存。栈内存中的变量无须系统垃圾回收,随方法或代码块的结束而结束。
Java允许局部变量和成员变量同名,方法局部变量会覆盖成员变量,如在方法里需引用成员变量,可使用this(实例变量)或类名(类变量)作为调用者来访问。
方法
- 方法不能独立定义,必须属于类或对象。
- 永远不能独立执行方法,执行方法必须使用类或对象作为调用者。
- Java里方法的参数传递只有值传递这一种,无论是基本类型的值的复制,还是引用类型在栈内存中引用变量的地址的值的复制。
- 静态方法中不能使用this关键字,不能直接调用非静态方法,以“类名.静态方法”的方式调用。
- 类的main主方法,是类的入口点,它定义了程序从何处开始,是静态的,调用其他方法也必须静态,且没有返回值。主方法的形参为数组,代表程序的n个参数。
- 类的构造方法:没有返回值,名称与类名称相同。Java类至少包含一个构造器,系统默认会提供一个无参数的构造器。构造器可重载。
形参个数可变的方法
1 | public static void test(int a,String... books){ |
构造器
- 用于在创建对象时执行初始化,被其他方法调用后返回该类的实例。
- 构造器的名字必须和类名相同。
- java类必须包含一个或一个以上的构造器,如没有显式定义,会自动生成一个默认构造器。一旦自定义构造器,系统就不再提供默认构造器。
- 构造器可重载,如存在构造器的相互调用,可使用this关键字调用。
面向对象的三大基本特征:封装(Encapsulation),继承(Inheritance)和多态(Polymorphism)。
封装
将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,而是通过该类所提供的方法来实现对内部信息的操作和访问。良好的封装可实现以下目的
- 隐藏类的实现细节
- 让使用者只能通过事先预定的方法来访问数据
- 可进行数据检查,保证对象信息的完整性
- 便于修改,提高代码的可维护性
Java提供了3个访问控制符,还有个不加任何访问控制符,提供了4个访问控制级别。
| 访问修饰符 | 同一个类 | 同包 | 不同包,子类 | 不同包,非子类 | 说明 |
|---|---|---|---|---|---|
| private | √ | 当前类访问权限,例如大部分成员变量修饰 | |||
| default | √ | √ | 包访问权限,使用时不指定修饰符即可 | ||
| protected | √ | √ | √ | 子类访问权限,例如希望被子类重写的方法修饰 | |
| public | √ | √ | √ | √ | 公共访问权限,例如构造器方法修饰 |
类(外部类)的访问控制符:
- public表示全局类,该类可以import到任何类内。
- default默认为保留类,只能被同一个包内的其他类引用。
- 1个java文件里最多只能有1个public类,且文件名必须和public类名相同。
包
一种管理类文件的机制,就是类包,避免类名称冲突。同一个包中的类相互访问可以不指定包名。包名全部小写,使用package关键字定义,使用import关键字导入。可以使用import static 导入类中类方法或类变量。
| 常用包 | 说明 |
|---|---|
| java.lang | java语言核心,String、Math、System、Thread等,系统自动导入 |
| java.util | java工具类/接口,集合框架类/接口,如Arrays、List、Set等 |
| java.net | java网络编程相关类/接口 |
| java.io | java输入输出变成相关类/接口 |
| java.sql | JDBC数据库编程相关类/接口 |
继承
1、Java继承使用extends关键字,本意拓展,只能单继承,最多只有一个直接父类,如未显式指定,默认拓展java.lang.Object类。
2、方法重写:子类包含与父类同名方法的现象被称为方法重写/覆盖(Override)。重写要遵循“两同两小一大”,“两同”方法名和形参列表相同,“两小”子类方法返回值类型要比父类更小或相等,子类声明抛出的异常类比父类更小或相等,“一大”子类方法的访问权限比父类更大或相等。
3、依赖super关键字,可以在子类方法中调用父类被覆盖的实例方法、实例变量,以及父类构造器。
当子类覆盖了父类实例方法/实例变量后,子类的对象将无法访问父类中被覆盖的实例方法/实例变量,但可以在子类方法中通过super调用父类被覆盖的实例方法/实例变量(实际是被隐藏了)。
在实例化子类对象时,子类不会获得父类构造器,但子类构造器可以调用父类构造器。
子类调用父类构造器分以下情况,无论如何,子类构造器总会调用父类构造器一次:
- 如使用super显式调用父类构造器(必须在第一行),系统根据super调用的实参列表调用父类对应的构造器。
- 如第一行使用this显式调用本类中重载的构造器,系统根据this调用的实参列表调用本类的另一个重载构造器,执行该构造器时会调用父类构造器。
- 如既没有super和this调用,会在子类的构造器之前,自动调用父类的无参构造方法。(父类的有参构造方法并不能被自动调用,只能依赖super关键字显式调用。)
4、所有类的基类,是java.lang.Object类。如创建类时无指定,则默认继承Object类。有几个重要方法:getClass().getname(); toString(); equals(); equals方法默认使用“==”运算符比较两个对象的引用地址,如需要比较两个对象的内容,需要在自定义类中重写equals()方法。
5、继承是“是”(is-a)的关系,组合是“有”(has-a)的关系。继承破坏封装,组合不会。
1 | package com.iherr.java.base.object; |
多态
1、Java引用变量有两个类型:编译时类型和运行时类型。编译时类型由声明决定,运行时类型由实际赋给变量的对象决定。当编译时类型与运行时类型不一致时,可能出现多态。多态只针对实例方法,不针对实例变量。
2、引用类型的转换,只能在具有继承关系的两个类型之间进行,没有继承关系的无法进行类型转换,否则编译时会出现错误。
向上转型:将子类对象看做是父类对象(子类是特殊的父类,比如鸟一定是动物)。由于向上转型是具体类到抽象类的转换,因此是安全的,可自动转换。
向下转型:将父类对象强制转换为某个子类对象时,需要强制类型转换。但可能产生ClassCastException异常,可使用instanceof运算符来判断父类对象实际是否为子类的实例,然后使用(type)运算符进行强制转换。
1 | result = object instanceof Class; |
3、多态:“一个接口,多种方法”。同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果,以此解决代码冗余问题。父类引用指向子类对象,调用方法时会调用子类的实现,而不是父类的实现。
编译类型是父类,运行类型是子类,当运行时调用该引用变量的方法时,其方法表现出子类方法的特征,就会出现相同类型的变量调用同一个方法呈现出不同的行为,这就是多态。
1 | Parent instance = new Child(); |
成员变量,编译看父类,运行看父类。(不具备多态)
成员方法,编译看父类,运行看子类,动态绑定。(具备多态)
静态方法,编译看父类,运行看父类。 (静态和类相关,算不上重写)
4、动态多态的三个条件:
- 继承的存在(继承是多态的基础,没有继承就没有多态)
- 子类重写父类的方法(多态下调用子类重写的方法)
- 父类引用变量指向子类对象(子类到父类的向上转型安全)
5、重载(overload)和重写(override)是实现多态的两种主要方式。
重载:不是严格意义上的多态,但可以看作是静态多态(编译时多态)。在同一个类允许同时存在一个以上的同名方法,只要这些方法的参数个数或类型不同即可。当只有返回类型时不同不足以区分重载。
1 | //重载 |
重写:可体现动态多态(运行时多态)。父类与子类有同样的方法名和参数。
1 | //重写 |
初始化块
- 构造器用于Java对象的状态初始化,也可使用初始化块来对Java对象进行初始化操作。
- 一个类里可以有多个初始化块,按顺序执行。
- 被static修饰的称为静态初始化块,不能访问非静态成员。
- 初始化块只在创建Java对象时隐式执行,且在执行构造器之前执行,且无法接收任何参数。
- 静态初始化块在类初始化阶段执行,而不是在创建对象时才执行,且只需执行一次。
1 | [修饰符] { |
static修饰符
- static关键字修饰的成员就是类成员,包括类变量、类方法、静态初始化块、内部类等。
- static不能修饰构造器,因为static修饰的成员属于整个类,而不是实例。
- 类成员不能访问实例成员,因为可能类成员初始化完成后,实例成员还未初始化。
- 可通过static修饰实例,和自定义静态方法来返回同一个实例,来实现单例。
- static方法内部不能使用this,不能调用非静态方法。但非静态方法里可以通过类本身调用静态方法。
final修饰符
final关键字可用于修饰类、变量和方法,表示修饰的类、方法和变量不可改变。通常final定义的变量为常量。一旦设定,不可改变变量的值。
1、final修饰成员变量,成员变量随类/对象的初始化而初始化,并分配默认值。final修饰后不可改变,因此java语法规定,final修饰的成员变量必须由程序员显式地指定初始值。成员变量的初始值可以在定义该变量时指定,其中类变量也可在静态初始化块中初始化,实例变量也可在构造器或非静态初始化中初始化,且只能指定一次。
2、final修饰局部变量,系统不会对局部变量进行初始化,因此使用final修饰局部变量时,可在定义时指定默认值,也可不指定。
3、final修饰基本类型变量和引用类型变量的区别:基本类型变量不能被改变,但对象引用也只能指向唯一一个对象,不可以再指向其他对象,但是一个对象本身的值确实可以改变的。
4、final方法:定义为final的方法不能被重写,可以被重载。如果是父类方法使用private final,子类可以生成新的相同的方法,但不是重写。
5、final类:定义为final的类不能被继承,如java.lang.Math类、StringBuffer类。
6、不可变类:8个包装类和String类都是不可变类。创建实例后,该实例的实例变量是不可改变的。final类不一定是不可变类,不可变类也不一定是final类。不可变类的定义方法如下:
- 用final和private来修饰成员变量
- 提供有参构造,来初始化成员变量
- 不提供setter方法
- 如有必要,重写equals和hashcode
抽象类
- 抽象类体现的是一种模板模式,从多个类中抽象出来的模板,只实现通用部分,不通用的部分抽象成抽象方法,留给子类实现。
- 使用abstract关键字,定义的类为抽象类,定义的方法为抽象方法,不能和final共用,也不能和static共用,不能修饰成员变量、局部变量、构造器等。
- 有抽象方法的类只能被定义成抽象类,抽象类里可以没有抽象方法。
- 抽象方法不能有方法体,连括号都没有,区别于空方法体。
- 抽放类可以包含成员变量、方法、构造器、初始化块和内部类(接口、枚举)5种成分。
- 抽放类不能被实例化,因此抽象类的构造器不能用于创建实例,主要用于被其子类调用。
- 抽象类只能当做父类被继承,且子类必须实现抽象类中的所有抽象方法。
1 | //抽象类体现的是一种模板模式,从多个类中抽象出来的模板,只实现通用部分,不通用的部分抽象成抽象方法,留给子类实现。 |
接口
- 接口是特殊(纯粹)的“抽象类”,体现的是规范和实现彻底分离的设计哲学。是开放的(public)且不能随意更改的(final)的规范。
- 接口使用interface关键字定义,一个类实现接口可以使用implements关键字。
- java规定一个类不能同时继承多个父类,但一个类可以同时实现多个接口,子类重写父类时访问权限只能更大或相等,因此实现类的方法只能是public。
- 修饰符可以是public或者省略,接口里的常量、方法、内部类和内部枚举都是public访问权限。
- 接口是一种规范,因此不能包含构造器和初始化块。成员变量必须是静态常量(系统会自动为接口内的成员变量增加static和final两个修饰符,只能在定义时指定默认值),方法只能是抽象方法(不修饰,自动增加public和abstract修饰符进行抽象)、类方法(static修饰)、默认方法(default修饰)和私有方法(private修饰,Java9功能)。
接口和抽象类的相同点:
- 都不能被实例化,位于继承树的顶端,用于被其他类实现和继承。
- 都可以包含抽象方法,实现接口或继承抽象类的子类必须实现这些抽象方法。
差异:
- 接口不能为普通方法提供方法实现,抽象类可包含普通方法。
- 接口里只能定义静态常量,不能定义普通成员变量。抽象类都可以。原因:一个类可以实现多个接口,会导致同名变量混淆。但一个类只能继承一个抽象类,不存在这个问题。
- 接口里不包含构造器,抽象类包含构造器,但只用于子类调用来完成抽象类的初始化。
- 接口里不包含初始化块,抽象类包含初始化块。
- 一个类可以实现多个接口,但一个类只能继承一个抽象类。
1 | //接口是特殊(纯粹)的“抽象类”,体现的是规范和实现彻底分离的设计哲学。是开放的(public)且不能随意更改的(final)的规范。 |
面向接口的编程:
- 简单工厂模式
- 命令模式
内部类
- 如果在类内部再定义一个类,被称为内部类。
- 根据定义的方式不同,内部类分为静态内部类(定义在类内部的静态类,例如HashMap内维护的Entry数组),成员内部类(定义在类内部的非静态类),局部内部类(定义在方法里的类),匿名内部类四种。
- 内部类比外部类多使用三个修饰符:private、protected、static。
- 内部类成员可直接访问外部类的私有数据。如果外部类成员变量、内部类非静态成员变量和内部类方法的局部变量同名,可使用this、外部类类名.this作为限定来区分。
- 外部类不能直接访问非静态内部类的实例变量,需要显式创建内部类对象才可访问。
- 使用static修饰的内部类称为静态内部类(类内部类),这个类时属于外部类本身,而不是某个外部类对象。
- 静态成员不能访问非静态成员,因此外部类的静态方法、静态代码块不能访问非静态内部类。会出现类加载时还没有创建内部类,就访问内部类实例的异常情况。
- 不允许在非静态内部类里定义静态成员。会导致该静态成员无法通过“外部类.内部类.静态变量”访问。
- 静态内部类里,可以包含静态成员和非静态成员。静态内部类不能访问外部类的实例成员,只能访问外部类的类成员。
内部类使用:
1 | class Outer { |
匿名内部类
- 匿名内部类必须继承一个父类或实现一个接口,最多只能一个。
- 匿名内部类不能是抽象类,在创建匿名内部类时会立即创建对象。并且这个类的定义会立即消失,匿名内部类不能重复使用。
- 匿名内部类不能定义构造器。没有类名,无法使用构造器。但可以定义初始化块。
1 | /* |
Lambda表达式(函数式编程)
- Lambda表达式为Java8新增,其目标类型必须是明确的函数式接口。Java8提供@FunctionalInterface注解,用于标记函数式接口,函数式接口只能有一个抽象方法,可以有默认方法或静态方法。
- 使用Lambda表达式来简化创建匿名内部类对象,Lambda支持将代码块作为方法参数,使用更简洁的代码来创建函数式接口的实例。
- Lambda包含形参列表、箭头(->)、代码块,省略了new Xxx(){}、重写的方法名字、重写方法的返回值。
- 当Lambda表达式的代码只有一条,可以使用方法引用和构造器引用。
Java8自带的函数式接口有:
| 函数接口 | 抽象方法 | 功能 |
|---|---|---|
| Predicate | boolean test(T t) | 判断真假 |
| Consumer | void accept(T t) | 消费消息 |
| Function | R apply(T t) | 转换 |
| Supplier | T get() | 生产消息 |
| UnaryOperator | T apply(T t) | 一元操作 |
| BinaryOperator | T apply(T t,T t2) | 二元操作 |
| Runnable/Thread | void run() | 多线程 |
1 | import java.util.Comparator; |
四、集合类
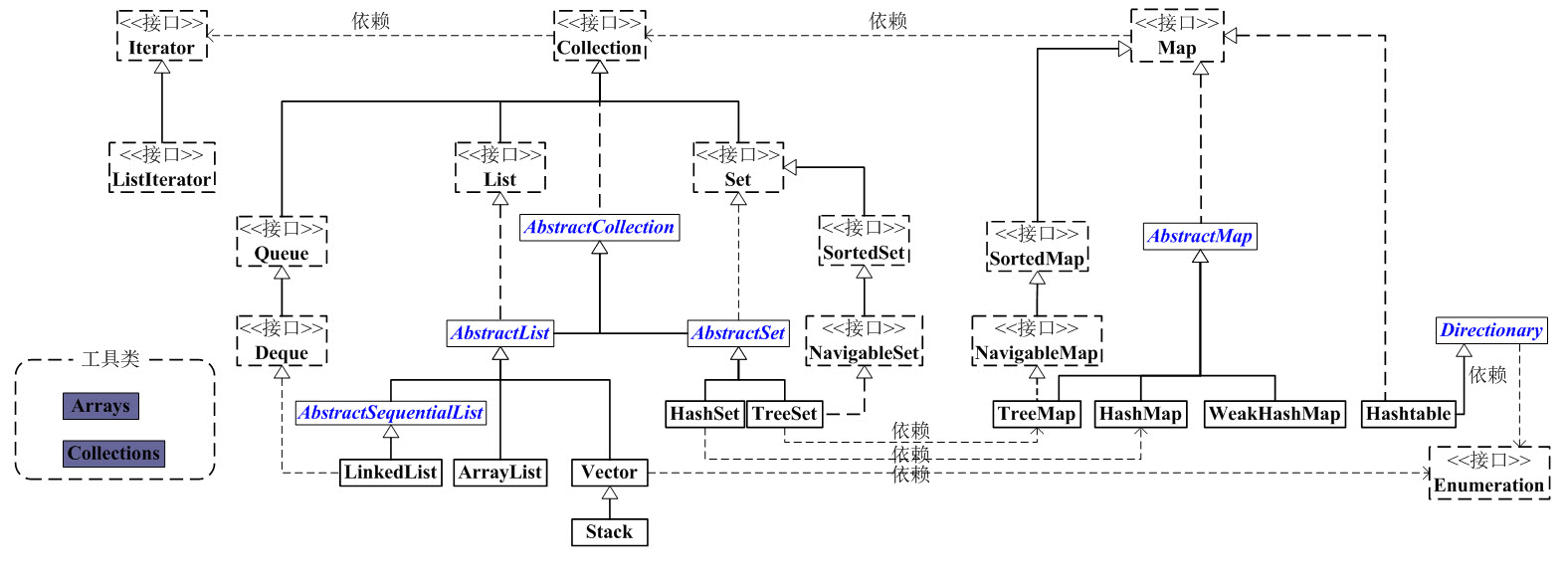
- 集合类用于存储数量不等的对象,可实现常用的数据类型,如栈、队列等。
- 集合和数组的区别:数组长度固定,集合长度可变。数组只能存储相同数据类型的数据,集合可以存储各种类型的数据。集合里不能放基本类型的值,但支持自动装箱。
- 集合分为Map和Collection(包含List、Set、Queue)。其中List允许重复且有顺序,Set无重复且无序,Queue队列。
| 接口 | 类 | 元素有序 | 允许重复 | 线程安全性 | 实现原理 | 容量大小 |
|---|---|---|---|---|---|---|
| List | ArrayList | 是 | 是 | 不安全 | 底层动态数组,适用频繁读取 | 默认构造容量为空初始扩容到10,后续扩容=当前容量*1.5+1 |
| List | LinkedList | 是 | 是 | 不安全 | 底层双向链表,适用插入和删除操作较多 | 没有初始化容量,无扩容机制 |
| List | Vector | 是 | 是 | 安全 | 底层动态数组,适用频繁读取,效率差不推荐 | 初始容量10,扩容=当前容量*2 |
| Map | HashMap | 否 | key唯一,value可重复 | 不安全 | 底层数组和单向链表,hash冲突时使用链表,JDK1.8时链表长度大于8转为红黑树 | 初始容量capacity=16,扩容因子loadFactor=0.75,达到扩容阈值threshold时容量扩大一倍到32。保持2的次幂。 |
| Map | LinkedHashMap | 是 | key唯一,value可重复 | 不安全 | 继承于HashMap,底层双向链表 | |
| Map | TreeMap | 是 | key唯一,value可重复 | 不安全 | 底层红黑树 | |
| Map | Hashtable | 否 | key唯一,value可重复 | 安全 | 底层哈希表,继承于Dictionary,效率差不推荐 | |
| Map | ConcurrentHashMap | 否 | key唯一,value可重复 | 安全 | 原理和HashMap类似,多个继承于ReentrantLock的分段锁Segment,默认有16个,用于线程并发 | |
| Set | HashSet | 否 | 否 | 不安全 | 底层哈希表,内部是HashMap,重复的判断原则是hashcode方法一样,equals方法也一样 | |
| Set | TreeSet | 是 | 否 | 不安全 | 底层红黑树,自定义对象需实现Comparable接口 | |
| Set | LinkedHashSet | 是 | 否 | 不安全 | 底层哈希表,用双向链表记录插入顺序,继承于HashSet,使用LinkedHashMap保存元素 |
Collection
Collection接口定义了add、addAll、remove、removeAll、clear、contains、isEmpty、iterator迭代器、size等操作集合元素的方法。
集合遍历
1 | Collection c =new ArrayList(); |
Set
常见实现类有HashSet、TreeSet和EnumSet类。都是线程不安全的,可通过Collections工具类的synchronizedSortedSet方法来包装实现同步。
1、HashSet
- 不保证迭代顺序,根据对象的hashCode()方法得到的hashCode值来决定存储位置,具备很好的存取和查找性能。
- 不是同步的,当多线程处理时需保证同步。
- 允许使用null元素。
- HashSet判断两个元素相等的标准是两个对象通过equal()方法比较相等,且两个对象的hashCode()返回值也相等。
- 有子类LinkedHashSet,还是按hashCode值来决定存储位置,但使用链表维护元素的次序,将会按元素添加顺序来访问集合里的元素。
2、TreeSet
- TreeSet是SortedSet接口的实现类,确保集合元素处于排序状态。
- TreeSet采用红黑树的数据结构来存储集合元素。支持两种排序方法:自然排序和定制排序。性能差
- 自然排序,按升序排列元素需要实现Comparable接口的compareTo方法,因此TreeSet只能添加同一种类型的对象。且判断相等的标准是两个对象的compareTo方法是否返回0。
- 定制排序,可在创建集合对象时,提供Comparator对象关联。
3、EnumSet
- 专门为枚举类设计的集合类,所有元素都必须是枚举类型的枚举值。
- 以位向量的形式存储,紧凑、高效。
- 不允许加入null元素。
1 | enum Season{ |
List
List是Collection接口的子接口。增加了一些根据索引来操作集合元素的方法。
- ArrayList和Vector都是List接口的实现,封装了可变数组,底层采用一个动态的、可重新分配的Object数组来存储集合元素,当元素集合超过该数组容量时,会重新再分配一个Object数组。
- Vector很古老,虽然线程安全,但不推荐使用。
- 如有多个线程同时访问元素,因为大部分都是线程不安全的,可以通过Collections工具类包装成线程安全。也可使用Concurrent开头的集合类,如ConcurrentHashMap等,支持并发访问,且写入线程的操作时线程安全的。
- 数组工具类Arrays的asList方法,是Arrays内部类ArrayList的实例,是固定长度。
- 此外还有LinkedList,实现了Deque接口,可作为List集合、双端队列、栈来使用。和基于数组的线性表ArrayList相比,LinkedList基于链表结构,插入/删除元素时性能出色,但随即访问元素时性能较差。
- 通常不需要考虑ArrayList和LinkedList性能差异,大部分情况考虑使用ArrayList。对于经常执行插入删除操作包含大量数据的List集合,可考虑使用LinkedList。
- 如需要遍历List集合元素,对于ArrayList和Vector,使用get方法来遍历集合,对于LinkedList,采用迭代器(Iterator)来遍历,这样性能更好。
- Enumeration接口是Iterator迭代器的古老版本,只能遍历Vector、HashTable这种古老的集合,不推荐使用。
1 | //ArrayList |
Queue集合
- Queue用于模拟队列,实现“先进先出”(FIFO)的容器。
- Queue接口定义了将元素加入队列尾部,获取队列头部元素等方法。
- Queue接口有一个PriorityQueue实现类,并且按照队列元素的大小重新排序。
Deque是Queue接口的子接口,代表双端队列,可以当成队列使用,也可当成栈来使用。
Deque方法与Queue和Stack的方法对照表如下:
| Queue方法 | Deque方法 | 说明 |
|---|---|---|
| add(e) | addLast(e) | 将元素添加到队尾,失败则抛出异常 |
| offer(e) | offerLast(e) | 将元素添加到队列尾部,失败则返回false |
| remove() | removeFirst() | 获取头部元素,删除该元素,失败则抛出异常 |
| poll() | pollFirst() | 获取头部元素,删除该元素,失败则返回false |
| element() | getFirst() | 获取头部元素,不删除该元素,失败则抛出异常 |
| peek() | peekFirst() | 获取头部元素,不删除该元素,失败则返回false |
| Stack方法 | Deque方法 | 说明 |
|---|---|---|
| push(e) | addFirst(e) | 将元素添加到队列头部,失败则抛出异常 |
| offerFirst(e) | 将元素添加到队列头部,失败则返回null | |
| pop() | removeFirst() | 获取头部元素,删除该元素,失败则抛出异常 |
| pollFirst() | 获取头部元素,删除该元素,失败则返回null | |
| peek() | getFirst() | 获取头部元素,不删除该元素,失败则抛出异常 |
| peekFirst() | 获取头部元素,不删除该元素,失败则返回null |
Deque接口提供的实现类为ArrayDeque,和ArrayList一样,底层采用一个动态的、可重新分配的Object[]数组来存储集合元素。
1 | // 1、当成栈使用 |
Map集合
- Map接口不继承Collection,提供key到value的映射,允许值对象为null,且没有个数限制。
- Map里的Key集,和Set集合关系密切,元素的存储形式很像。Map里的Value集,和List集合也类似。
- HashMap和Hashtable都是Map接口的典型实现,Hashtable是古老的,线程安全的。HashMap性能高,但线程不安全。类似于ArrayList和Vector的关系。HashMap允许使用null作为key或value,但因为无法调用hashcode方法,强制存放在第0个桶。
- 用作HashMap的key的对象必须实现hashCode()和equal()方法。判断两个key是否相等需要两个方法同时满足。
- LinkedHashMap,是HashMap的子类。还是按hashCode值来决定存储位置,但使用双向链表维护元素的次序,将会按元素添加顺序来访问集合里的元素。
1 | Map map=new HashMap(); |
HashMap原理:
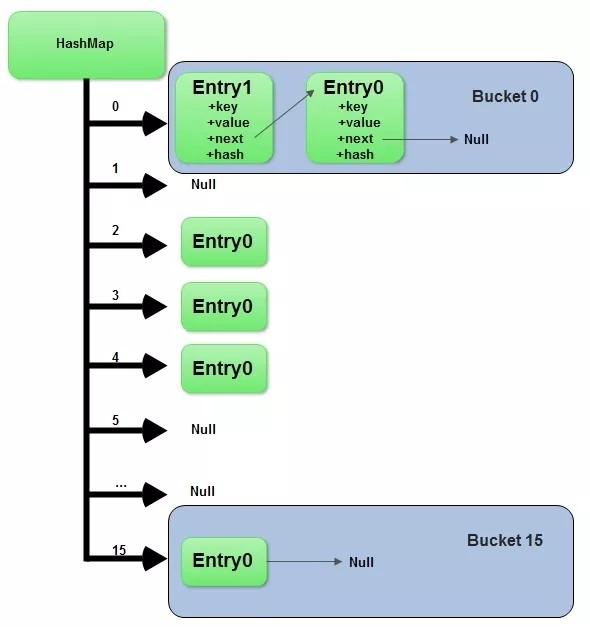
- 哈希桶数组Node[] table初始化长度length为16,负载因子loadFactor默认为0.75。容纳的键值对的极限threshold=16*0.75=12。
- 当装载的键值超过这个数目(如13个)会进行扩容rehash。哈希桶数组的长度加倍,且扩容时不需要重新计算hash,只需要看hash值新增的那个bit,如是0索引不变,是1的话,索引也加一位1。
- 存储桶位置确定算法

1 | static final int hash(Object key) { |
其他实现类:
- Properties类是HashMap的子类,增加load、store、setProperty、getProperty等操作。
- SortedMap是Map接口的子接口,SortedMap接口有TreeMap实现类。和TreeSet一样,是红黑树数据结构,需要根据key对节点进行排序。TreeMap的所有key必须实现Comparable接口。
- WeakHashMap实现类,WeakHashMap的key只保留了对实际对象的弱引用,可能会被垃圾回收。而HashMap的key保留了对实际对象的强引用,HashMap对象不被销毁则key所引用的对象不会被垃圾回收。
- IdentityHashMap实现类,判断key是否相等,采用严格相等(key1==key2),而HashMap则使用equals和hashCode方法来判断。
- EnumMap实现类,要求所有的key必须是单个枚举类的枚举值,内部以数组形式保存。创建时必须制定一个枚举类。
Collections工具类
Collections工具类提供了大量方法对集合元素进行排序、查询和修改操作,还提供将集合对象设置为不可变、同步控制等方法。
1、排序、查找、替换操作
1 | ArrayList nums= new ArrayList(); |
2、同步控制,解决多线程并发访问集合时的线程安全问题
1 | List list= Collections.synchronizedList(new ArrayList()); |
3、不可变集
1 | List unmodifiedList = Collections.emptyList(); |
五、泛型(Generic)
泛型使用
- Java集合有个缺点,把一个对象放进集合,集合会忘记对象的数据类型。当再次取出该对象时,该对象的编译类型变成Object类型(运行时类型没变)。
- 所谓泛型,就是允许在定义类、接口、方法时使用泛型形参(区别于数据形参),在声明变量、创建对象、调用方法时动态地指定。泛型形参可当成类型使用。
- Java7开始,允许在构造器后不需要带完整的泛型信息,只需要一对尖括号(<>),称为菱形语法。Java9开始允许在创建匿名内部类时使用菱形语法。
- 泛型指的是程序员定义安全的类型。Java提供了对Object的引用“任意化”操作,进行向上转型以及向下转型。
- 不管泛型形参传入哪一种类型实参,对Java来讲都是同一个类来处理,因此在静态方法、静态初始化块、静态变量的声明和初始化中,不允许使用泛型形参。
- 数组和泛型不同,假设Foo是Bar的子类型,那么Foo[]依然是Bar[]的子类型,但G
不是G 的子类型,Foo[]自动向上转型为Bar[],称为型变。因此数组支持型变,集合不支持型变。 - 泛型只在编译阶段有效。泛型的设计原则,只要代码在编译时没有出现警告,就不会碰到运行时ClassCastException异常。在运行时只有调用者知道需要什么类型,且调用者调用泛型方法后自己做强制转换,被调用者是完全无感的。
1、常用的被泛型化的集合类:
| 集合类 | 泛型定义 |
|---|---|
| ArrayList | ArrayList<E> |
| HashMap | HashMap<K,V> |
| HashSet | HashSet<E> |
| Vector | Vector<E> |
1 | List<String> books= new ArrayList<>(); |
2、可以为任何类、接口增加泛型声明,Generic
1 | class Generic<T> { |
类型通配符
1 | List<?>// 相当于List<? extends Object> |
1、为什么要用通配符和边界?
使用泛型的过程中,经常出现一种很别扭的情况。比如我们有Fruit类,和它的派生类Apple类。
1 | class Fruit {} |
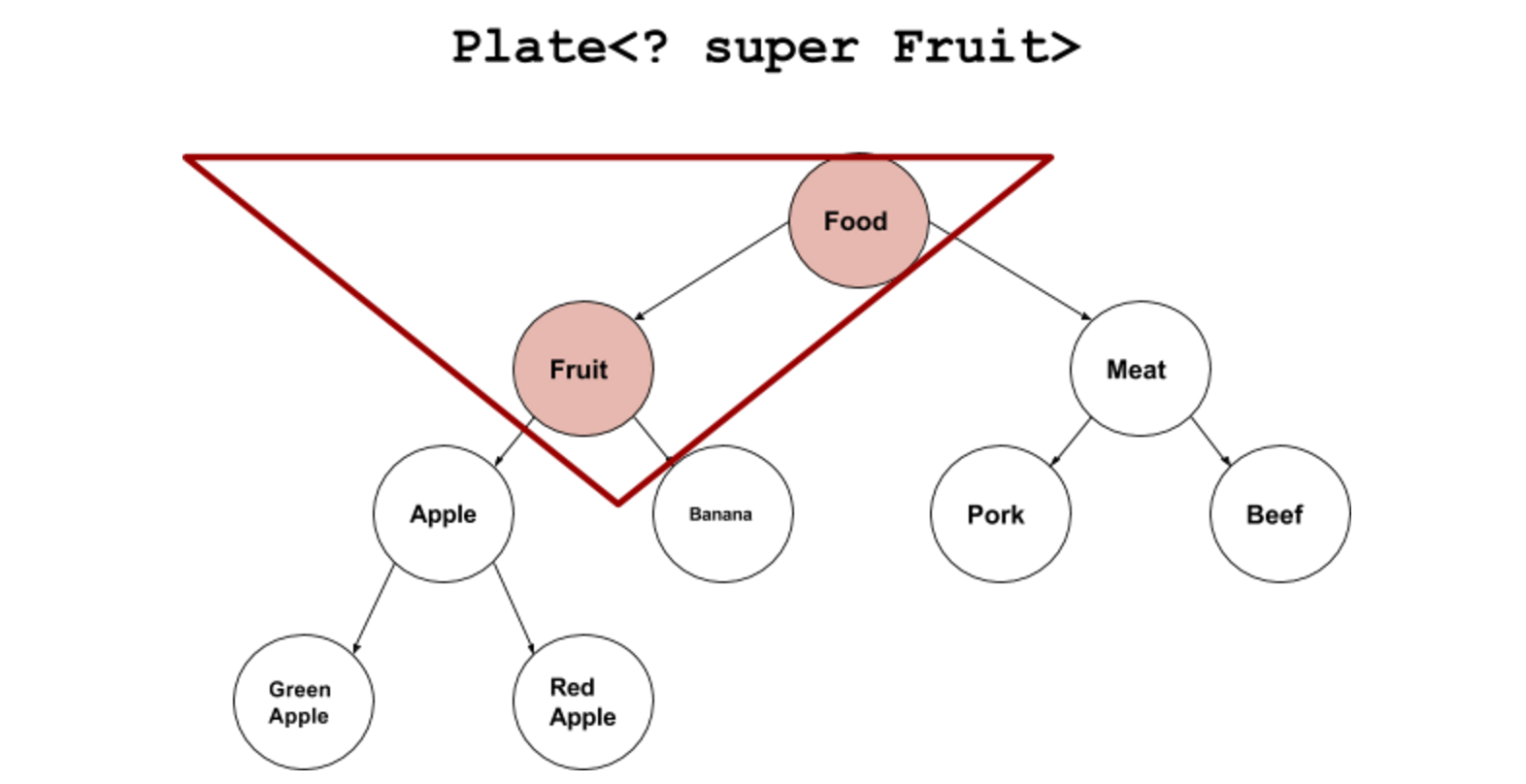
然后有一个最简单的容器:Plate类。盘子里可以放一个泛型的“东西”。我们可以对这个东西做最简单的“放”和“取”的动作。
1 | class Plate<T>{ |
现在我定义一个“水果盘子”,逻辑上水果盘子当然可以装苹果。
Plate
但实际上Java编译器不允许这个操作。会报错,“装苹果的盘子”无法转换成“装水果的盘子”。
1 | error: incompatible types: Plate<Apple> cannot be converted to Plate<Fruit> |
实际上,编译器脑袋里认定的逻辑是这样的:
- 苹果 IS-A 水果
- 装苹果的盘子 NOT IS-A 装水果的盘子
所以,就算容器里装的东西之间有继承关系,但容器之间是没有继承关系的。所以我们不可以把Plate的引用传递给Plate。
为了让泛型用起来更舒服,Sun的大脑袋们就想出了<? extends T>和<? super T>的办法,来让”水果盘子“和”苹果盘子“之间发生关系。其中?代表不确定的类型。
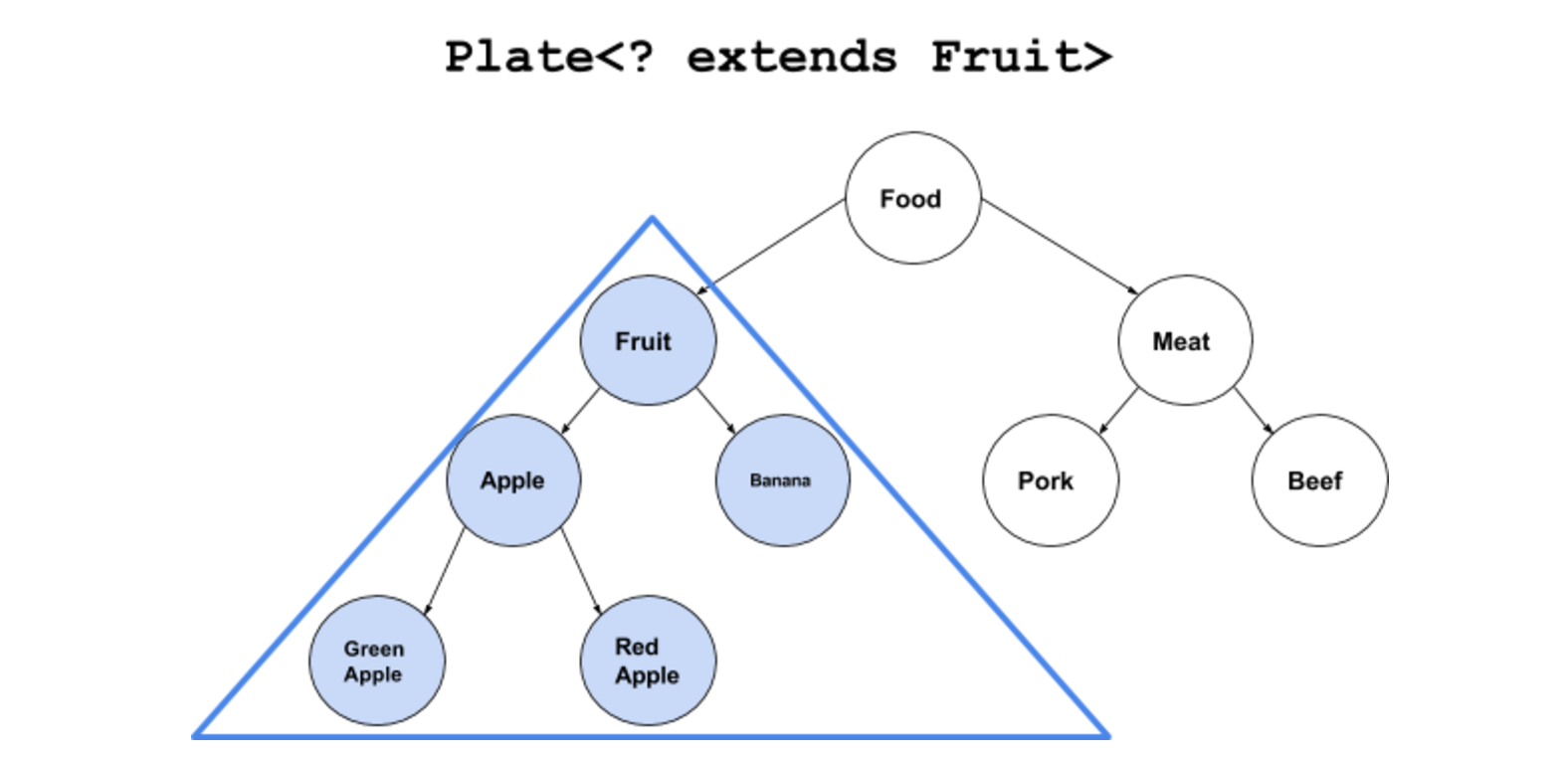
2、上界通配符(Upper Bounds Wildcards),用于表示实例化时可以确定父类型的未知类型
1 | Plate<? extends Fruit> |
翻译成人话就是:一个能放水果以及一切是水果派生类的盘子。再直白点就是:啥水果都能放的盘子。指定通配符上限是为了支持协变,比如Fruit是Apple的父类,但Plate
1 | Plate<? extends Fruit> p=new Plate<Apple>(new Apple()); |
3、下界通配符(Lower Bounds Wildcards),用于表示实例化时可以确定子类型的未知类型
1 | Plate<? super Fruit> |
表达的就是相反的概念:一个能放水果以及一切是水果基类的盘子。Plate<? super Fruit>是Plate
4、上下界通配符的副作用
边界让Java不同泛型之间的转换更容易了。但不要忘记,这样的转换也有一定的副作用。那就是容器的部分功能可能失效。
还是以刚才的Plate为例。我们可以对盘子做两件事,往盘子里set新东西,以及从盘子里get东西。
extends上界通配符不能往里存,只能往外取。会使往盘子里放东西的set()方法失效。但取东西get()方法还有效。比如下面例子里两个set()方法,插入Apple和Fruit都报错。
1 | Plate<Fruit> p=new Plate<Fruit>(); //正常 |
下界<? super T>不影响往里存,但往外取只能放在Object对象里
使用下界<? super Fruit>会使从盘子里取东西的get( )方法部分失效,只能存放到Object对象里。set( )方法正常。
1 | Plate<? super Fruit> p5=new Plate<Food>(); //正常,必须是水果的基类。使用了下界通配符(Lower Bounds Wildcards) |
5、总结
数组是协变的。泛型是不变的,泛型可通过通配符来支持协变和逆变。
直观上会错误的认为, Apple是Fruit的子类, 所以List
泛型支持协变则需要引入上界通配符extends。实例出来的对象,只能删除和读取(元素总是上限的类型,可赋值给基类),不能添加元素(比如不能把fruit对象赋值给apple)。
泛型支持逆变则需要引入下界通配符super,只能添加元素(fruit对象可以赋值给基类),读取元素只能赋值给Object。
PECS(Producer Extends Consumer Super)原则:
- 频繁往外读取内容的,适合用上界Extends的协变。
- 经常往里插入的,适合用下界Super的逆变。
泛型方法
- 泛型方法定义了一个T泛型形参,定义在方法装饰符后面,这个T类型就可以在该方法内当成普通类型使用。
- 泛型方法只能在该方法里使用,而接口、类声明中定义的泛型则可以在整个接口、类中使用。
- 大多数时候都可以使用泛型方法来代替类型通配符。
- 泛型方法中定义的T后,如果类中也有T,它们是没有任何关系的,不受类的泛型的影响。
1 | import java.util.ArrayList; |
六、类的加载机制和反射
反射
- 反射是框架设计的灵魂,java可以算是半动态语言。
- JAVA反射机制,是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
- 反射的原理,就是java类对应的字节码文件中,找到唯一的Class对象,然后将成员变量、方法、构造、包等各种成分映射成一个个的Java对象。
Class类
- Class类也是类的一种,与class关键字是不一样的
- 类被编译后的字节码class文件中会产生一个Class对象,其表示的是创建的类的类型信息,而且这个Class对象保存在同名.class的字节码文件中
- 每个通过关键字class标识的类,在内存中有且只有一个与之对应的Class对象来描述其类型信息,无论创建多少个实例对象,其依据的都是用一个Class对象。
- Class类只存私有构造函数,因此对应Class对象只能由JVM创建和加载
- Class类的对象作用是运行时提供或获得某个对象的类型信息,这点对于反射技术很重要
类的加载、连接和初始化
- 当调用java运行某个java程序时,将会启动JVM进程,同一个JVM的所有线程、变量都处于该进程,共同使用JVM进程的内存区。当Java程序运行结束时,JVM进程结束,该进程在内存中状态将会丢失。
- 当程序使用某个类时,如果该类还未被加载到内存中,会通过加载、连接、初始化三个步骤对类进行初始化。
- 类的加载由类加载器class loader(通常由JVM提供,有BootstrapClassLoader,ExtClassLoader,AppClassLoader)完成,可预加载,可以从本地class文件、jar包class文件、网络class文件、动态编译源文件并动态加载等方式。会根据类名查找对应的.class文件,找到编译后的class对象,该对象表示的是创建的类的类型信息。
- 类的连接,会把类的二进制数据合并到JRE中。
- 类的初始化,由虚拟机对类变量进行初始化。
- 当Java程序首次通过以下方式来使用某类或接口时,系统就会初始化该类或接口。(1)创建类的实例 (2)调用类的类方法(3)访问类的类变量或赋值 (4)使用反射方式强制创建类对应的java.lang.Class对象。(5)初始化某类的子类(6)使用java命令运行某个主类
双亲委派,当一个类加载器收到类加载任务时,会先交给自己的父加载器去尝试从缓存加载,最终会传递到最顶层的BootstrapClassLoader,只有当父加载器无法完成加载任务时,才会尝试自己来加载。采用双亲委派模型的一个好处是保证使用不同类加载器最终得到的都是同一个对象,保证Java核心库的类型安全。
1 | //ClassLoader源码 |
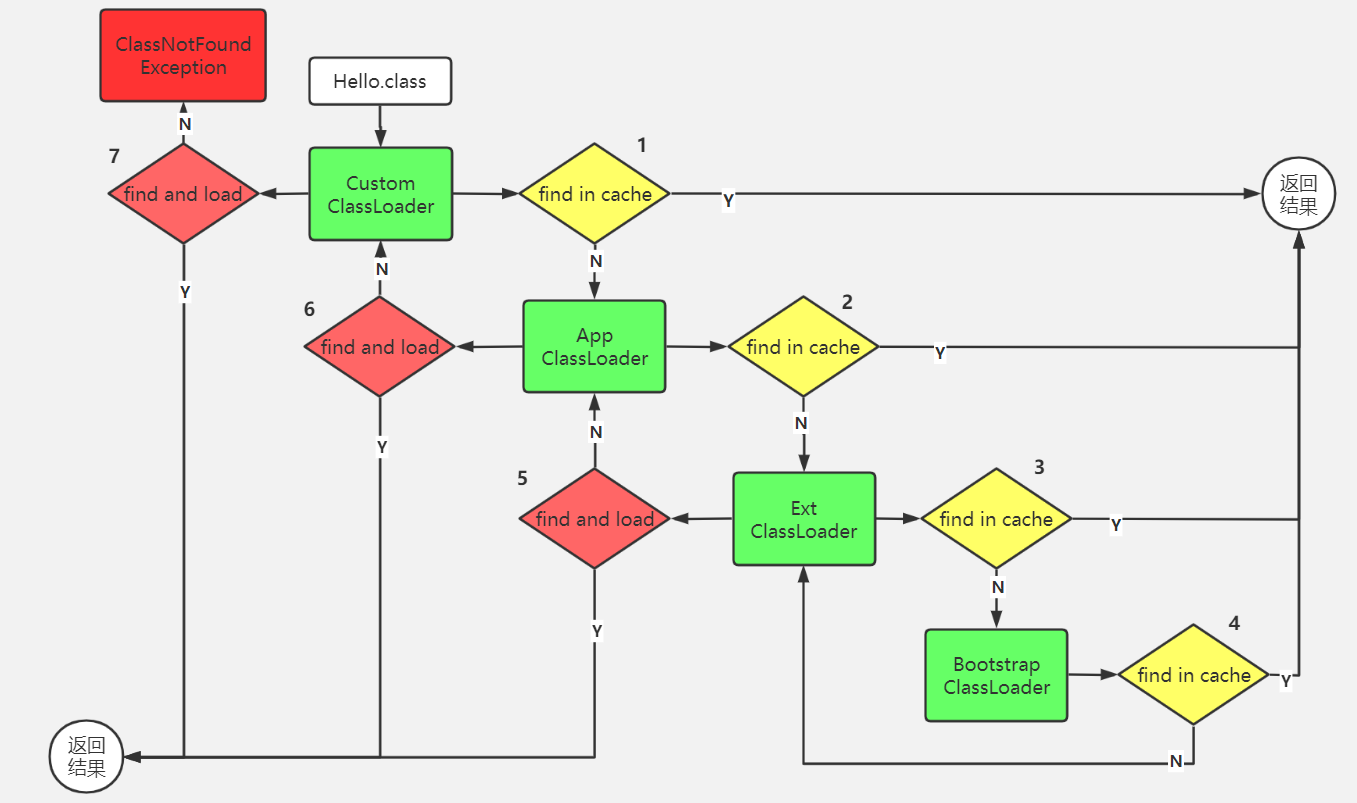
但双亲委派模型并不能解决所有的类加载器问题,比如,Java 提供了很多服务提供者接口(Service Provider Interface,SPI),如有 JDBC、JNDI、JAXP等,允许第三方为这些接口提供实现。这些SPI的接口由核心类库提供,却由第三方实现,这样就存在一个问题:SPI 的接口是 Java 核心库的一部分,是由BootstrapClassLoader加载的。SPI的实现类一般是由AppClassLoader来加载的。BootstrapClassLoader是无法找到 SPI 的实现类的,因为它只加载Java的核心库。它也不能代理给AppClassLoader,因为它是最顶层的类加载器。也就是说,双亲委派模型并不能解决这个问题。Spring使用线程上下文类加载器 ContextClassLoader来解决这个问题。
使用反射生成并操作对象
1 | public class Person { |
1 | import com.iherr.java.base.entity.Person; |
动态代理
- 代理是一种模式,为其他对象提供一个代理以控制对某个对象的访问,分为静态代理和动态代理。代理类主要负责为委托了(真实对象)预处理消息、过滤消息、传递消息给委托类,代理类不现实具体服务,而是利用委托类来完成服务,并将执行结果封装处理。
- 静态代理,是用代码手动创建的代理类,在编译期就生成了代理类,运行时已完成创建并生成class文件。但是静态代理的缺点也暴露了出来,由于代理只能为一个类服务,如果需要代理的类很多,或者1个代理类有多个方法,那么就需要编写大量的代理类和逻辑处理,比较繁琐。AspectJ就是基于静态代理的一个面向切面的框架。
- 动态代理,是利用反射机制在运行时创建代理类。有以下几种实现方式,基于JDK的动态代理,和基于CGLIB的动态代理,基于instrumentation实现动态代理等。JDK的动态代理基于接口。CGLIB是基于继承,用到asm字节修改技术,针对类的代理创建子类来实现增强,使用更加广泛。
- 动态代理是实现AOP的方式,可以非常灵活的实现解耦。AOP的源码中JDK和CGLIB都用到。
以下为静态代理的实现方式:
1 | // 公共接口 |
基于JDK的动态代理,实现一定要继承一个接口。是构建一个handler类来实现InvocationHandler接口,通过JDK工具方法Proxy.newProxyInstance方法构建动态代理类(继承Proxy类,并持有handler接口引用),并实例化对象返回。使得当执行动态代理类对象的方法时都会调用InvocationHandler对象的invoke()方法。具体步骤:
- 公共接口和委托类,和静态代理一致,不需要修改
- 通过实现InvocationHandler接口创建自己的调用处理器,是被动态代理类回调的接口,所有针对委托类的逻辑都增加到接口重写的invoke方法中,调用委托类接口方法的前后。
- 通过为Proxy类指定ClassLoader对象和一组interface来创建动态代理类,返回class实例代表一个class文件,并继承Proxy类。
- 通过反射机制获得动态代理类的默认构造函数,其唯一参数是InvocationHandler类型,创建动态代理类实例并返回。
1 | import java.lang.reflect.InvocationHandler; |
基于CGLib的动态代理,需要引入cglib包
1 | import net.sf.cglib.proxy.Enhancer; |
七、注解
注解是一个接口,用来为程序元素(类、方法、成员变量)设置元数据(MetaData)。程序可以通过反射来获取元素的Annotation对象,然后通过该对象提取注解里的元数据。
常用注解
- @Override,限定重写父类方法。只能修饰方法,如子类某个被修饰的方法没有重写,会编译报错。
- @Deprecated,类、方法过时,给出编译警告。Java9增加两个属性,forRemoval 将来是否会删除,since,从哪个版本过时。
- @SuppressWarnings,抑制编译器警告。
- @SageVarargs,堆污染警告
- @FunctionalInterface,函数式接口
JDK的元注解
元注解的作用是负责注解其他注解。
1、@Retention,指定被修饰的注解可以保留多长时间。包含一个RetentionPolicy类型的value成员变量。
- RetentionPolicy.CLASS,默认值,编译器把注解记录在class文件中,且运行时JVM不可获取注解信息。
- RetentionPolicy.RUNTIME,编译器把注解记录在class文件中,且运行时JVM可获取注解信息,程序可以通过反射获取该注解信息。
- RetentionPolicy.SOURCE,只保留在源码,编译器直接丢弃这种注解。
2、@Target,指定被修饰的注解能用于修饰哪些程序单元。包含一个名为value的成员变量。
- ElementType.ANNOTATION_TYPE,只能修饰注解
- ElementType.CONSTRUCTOR,只能修饰构造器
- ElementType.FIELD,只能修饰成员变量
- ElementType.LOCAL_VARIABLE,只能修饰局部变量
- ElementType.METHOD,只能修饰方法定义
- ElementType.PACKAGE,只能修饰包定义
- ElementType.PARAMETER,只能修饰参数
- ElementType.TYPE,只能修饰类、接口(注解类型)、枚举定义
java8新增TYPE_PARAMETER和TYPE_USE两个枚举值,类型注解,可用于修饰在任何地方出现的类型。
3、@Document,用于指定该注解将被javadoc工具提取成文档。
4、@Inherited,指定被它修饰的注解将具有继承性,使用在类上面时,子类会自动继承该注解。
自定义注解
- 使用@Interface定义注解,可在注解里定义成员变量。
- 根据是否包含成员变量,分为标记注解和元数据注解。
- 在程序中仅使用注解是不会起到任何作用的,需要使用注解处理器来处理注解。APT(Annotation Processing Tool)是一种注解处理器。每个注解处理器都需要实现javax.annotation.processing包下的Processor接口。可使用javac -processor命令来选择注解处理器并编译。
1 | import java.lang.annotation.*; |
八、I/O(输入Input/输出Output)
IO指的是读出/写入数据,可分为磁盘IO和网络IO。
网络IO(网络通信)
- 网络IO包括了等待数据传输和读写数据的过程,等待数据传输其实就是等待数据经由网线、网卡、内核空间的过程,读写数据的过程是内核空间和用户空间的互相拷贝的过程。
- 网络IO就是通过套接字(socket)来进行通信的。套接字为两台计算机之间的网络通信提供了一种机制,用于表达两台机器之间的连接“终端”。可以想象它们之间有一条虚拟的“电缆”,“电缆”的每一端都插入到套接字中。当然,机器之间的物理硬件和电缆连接都是完全未知的。它是一种软件抽象,抽象的全部目的是使我们无须知道不必知道的细节。
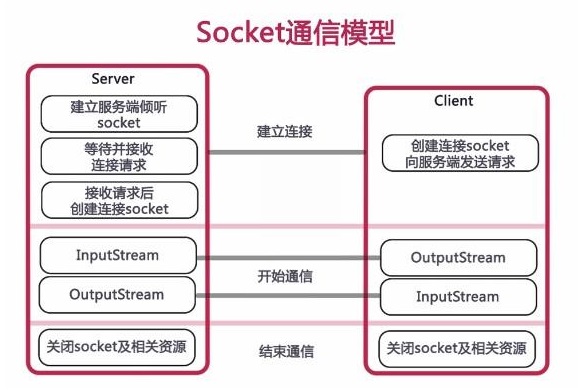
- 套接字大致驻留在OSI模型的会话层,会话层夹在其上面向应用的层和其下的实时数据通信层之间,为两台计算机之间的数据流提供管理和控制服务。Socket是TCP/IP协议的一个具体的实现。
- Java的TCP协议套接字实现分为ServerSocket和Socket两个类,ServerSocket用于服务器端套接字,通过制定端口并监听请求,来等待网络上的请求连接的套接字。客户端直接使用Socket发起请求并传输数据,两者相互配合,进行消息传递。
- UDP协议传输不可靠,无法知道是否送达。Java使用DatagramSocket类创建数据包套接字,使用DatagramPacket创建和接收数据包。使用DatagramSocket的send()发送数据包,使用DatagramPacket的receive()方法接收UDP包。
1 | import java.io.*; |
输入流和输出流
- 流,是一组有序的数据序列,按照流的流向分为输入流和输出流,一边是文件、网络、压缩包或其他数据源,另一边是目的地或源。
- 所有输入流都是抽象类InputStream(字节输入流,8位的字节)或抽象类Reader(字符输入流,16位的字符)。所有输出流都是抽象类OutputStream(字节输出流)或抽象类Writer(字符输出流)。
- 按照流的角色可分为节点流和处理流(用来包装节点流)。
- Java流的类都在java.io包中。
- Java以UTF-16作为内存的字符存储格式Java字符,是Unicode编码双字节。
- 通常来说,字节流的功能比字符流强大,字节流可以处理计算机里所有的数据(都是二进制)。但如果使用字节流处理文本,需要把字节转换成字符,增加了变成的复杂度。因此字符文本的处理应该考虑使用字符流Reader或Writer,二进制内容的处理应该考虑使用字节流InputStream或OutputStream。
以下为输入输出流体系:
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类(抽象类) | InputStream | OutputStream | Reader | Writer |
| 访问文件(节点流) | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组(节点流) | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道(节点流) | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串(节点流) | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 抽象基类(抽象类) | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
1、字节流
InputStream包含read()读取下一个字节、read(byte[] b)读取一定长度的字节,mark(int readlimit)允许当前位置作标记,reset()返回标记处,skip()跳过输入流上的n个字节,close()方法关闭输入流并释放系统资源。
OutputStream包含write(int b)讲指定的字节写入输出流,flush()彻底完成输出并清空缓存区,close()方法关闭输出流。
2、文件流
File类,使用File(String pathname)来创建文件,可获取文件的信息,getName,canWrite,exits,length,isHidden,lastModified等。
文件输入/输出流:FileInputStream/FileOutputStream。最好使用FileReader和FileWriter类,因为汉字也占两个字节,如果使用字节流可能会出现乱码。
3、缓存流
带缓存的输入/输出流:缓存是I/O的一种性能优化。缓存流为I/O流增加了内存缓存区,使得在流上执行skip、mark、reset等操作。BufferedInputStream/BufferedOutputStream和BufferedWriter/BufferedReader。
文件–> InputStream –> BufferedInputStream –> 目的地
BufferedInputStream比InputStream多一个flush()方法来将缓存区的数据强制输出完。
BufferedInputStream构造方法:
BufferedInputStream(InputStream in);//默认32字节
BufferedInputStream(InputStream in,int size);
BufferedReader增加readLine()。
4、数据流
数据输入/输出流:允许应用程序以与机器无关的方式读取数据。DataInputStream和DataOutputStream。
5、zip压缩流
zip压缩输入/输出流:允许应用程序使用zip文件压缩节省存储空间。ZipInputStream和ZipOutputStream。
6、处理流
使用处理流时的典型思路是,不直接使用节点流,可使用处理流来包装节点流,程序通过处理流来执行输出/输入功能。
例如使用PrintStream来包装OutputStream。
7、转换流
用于将字节流转换成字符流。InputStreamReader将字节输入流转换成字符输入流。OutputStreamWriter将字节输出流转换成字符输出流。
8、推回输入流
都带有一个推回缓冲区,使用unread方法将内容推回到推回缓冲区里,从而允许重复读取。
1 | public class StreamIOBasic { |
1 | public class ReaderBasic { |
阻塞、非阻塞、同步、异步、中断等基本概念
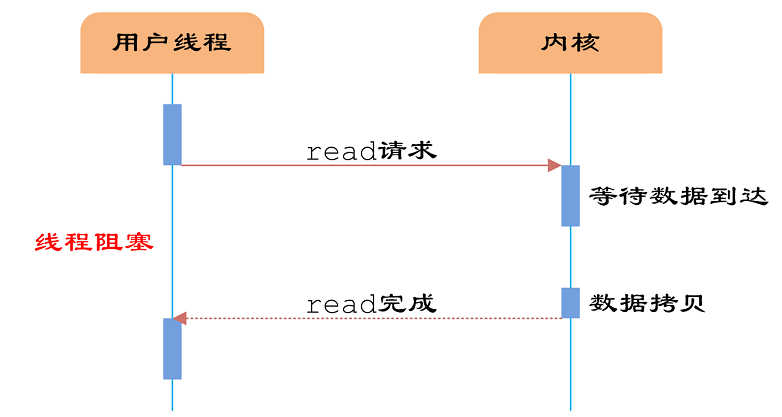
- 阻塞,非阻塞,是描述调用方的。用来描述进程处理调用的方式,主要指Socket的阻塞,本质是IO操作。阻塞方式为,调用结果返回之前,当前线程从运动状态被挂起,一直等到调用结果返回之后,才进入就绪,获取cpu继续执行。而非阻塞如果结果不能马上返回,当前线程也不会被挂起,而是立即返回执行下一个调用。
- 同步、异步,是描述被调用方的。
- IO调用会形成同步阻塞方式、异步阻塞方式、同步非阻塞方式、异步非阻塞方式。同步不一定阻塞,异步也不一定非阻塞。没有必然关系。
举个简单的例子,老张烧水。
- (同步阻塞)老张把水壶放到火上,一直在水壶旁等着水开。
- (同步非阻塞)老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。
- (异步阻塞)老张把响水壶放到火上,一直在水壶旁等着水开。
- (异步非阻塞)老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。
1和2的区别是,调用方在得到返回之前所做的事情不一样。 1和3的区别是,被调用方对于烧水的处理不一样。
内核接收数据的全过程描述如下:
- 等待数据:进程A拥有CPU资源,当它执行到socket生成一个socket对象(包含接收buffer、发送buffer、等待队列),继续执行到recv()方法时,操作系统将进程A从工作队列移到等待队列,其他进程继续轮流执行,A被阻塞,不往下执行代码,也不占用CPU资源。
- 数据来了:网络数据经由网卡传进内存,网卡驱动中断信号,CPU做出响应,执行中断程序,socket接收数据。
- 唤醒进程:socket收到数据后,操作系统将该socket的等待队列中的进程A的状态改为“运行中”,进程回到工作队列中继续执行代码。由于socket的接收buffer有了数据,recv()方法返回接收到的数据。
BIO、NIO、AIO等IO模型
1、BIO(Blocking IO)
BIO是同步阻塞式IO,是传统的IO模型,java使用原生的Socket来实现。服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
1 |
|
2、NIO(Non-blocking IO),并非java的NIO库
NIO是同步非阻塞式IO,是相当于BIO来说的,是为了降低线程开销的问题产生的,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
NIO不等于高性能,当连接数<1000,并发程度不高或者局域网环境下NIO并没有显著的性能优势。
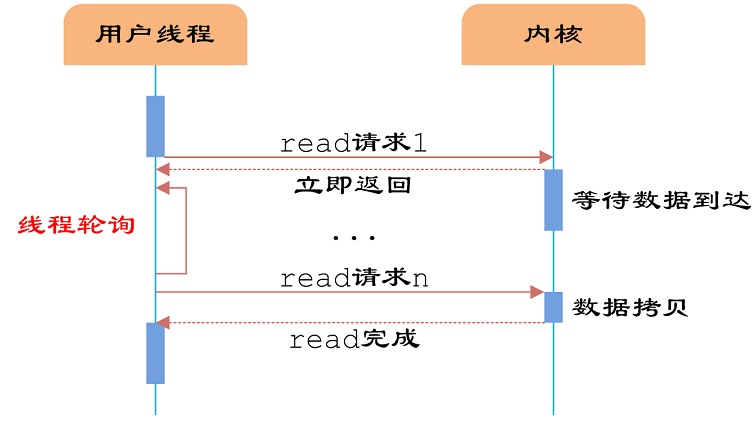
1 | //单线程处理多连接 |
I/O多路复用(IO Multiplexing)
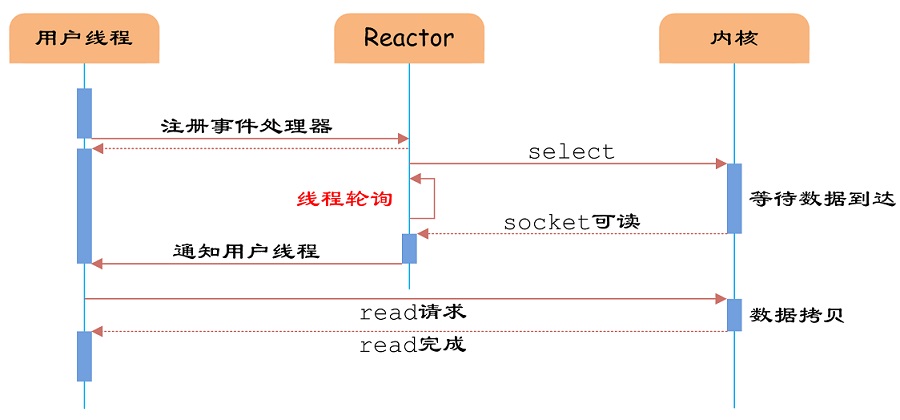
I/O多路复用仍然是NIO。只是上面的NIO,仅仅是将原来的同步阻塞IO优化成了同步非阻塞IO,既然还是同步的,就意味着我们每次遍历,还是需要对每个Socket进行一次read操作来检查是不是有数据过来,都会调用系统内核的read指令,只不过是把阻塞变成了非阻塞,如果无用连接很多的话,那么绝大部分的read指令都是无意义的,这就会占用很多的CPU时间。
IO多路复用模型使用了Reactor设计模式实现了这一机制。
Linux有select、poll和epoll三个解决方案来实现多路复用。
select和poll,有点类似于上面的NIOServer程序,他会把所有的文件描述符记录在一个数组中,通过在系统内核中遍历来筛选出有数据过来的Socket,只不过是从应用程序中遍历改成了在内核中遍历,本质还是一样的。
select模式的特点:
- 单个进程监测的fd受限制,默认下是1024个文件描述符;
- 轮询式检查文件描述符集合中的每个fd可读可写状态,IO效率会随着描述符集合增大而降低;
- 可以采用一个父进程专门accept,父进程均衡的分配多个子进程分别处理一部分的链接,子进程采用select模型监测自己负责的fd的可读可写。
当有大量连接与该进程保持,但每一时刻仅有一小部分连接是活跃的时候,内核寻找这些连接上有没有未处理的事件,如select和poll会循环遍历,将会是巨大的资源浪费,因此它们最多只能处理几千个并发连接。
Epoll则使用了事件机制,在复用器中注册了一个回调事件,当Socket中有数据过来的时候调用,通知用户处理信息,这样就不需要对全部的文件描述符进行轮训了,这就是Epoll对NIO进行的改进。
epoll工作流程:
- 调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
- 调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
- 调用epoll_wait收集发生事件的连接。
epoll模式的特点:
- 支持进程打开的最大文件描述符,很好的解决了C10K问题;
- IO效率不随FD数目增加而线性下降,epoll不是通过轮询,而是通过在等待的描述符上注册回调函数,当事件发生时,回调函数负责把发生的事件存储在就绪事件链表中,最后写到用户空间;
- 使用mmap加速内核与用户空间的消息传递
Java调用了操作系统的Api来创建Socket,获取到Socket的文件描述符,再创建一个Selector对象,对应操作系统的EPoll描述符,将获取到的Socket连接的文件描述符的事件绑定到Selector对应的EPoll文件描述符上,进行事件的异步通知,这样就实现了使用一条线程,并且不需要太多的无效的遍历,将事件处理交给了操作系统内核,大大提高了效率。
1 | public class NioEpollServer { |
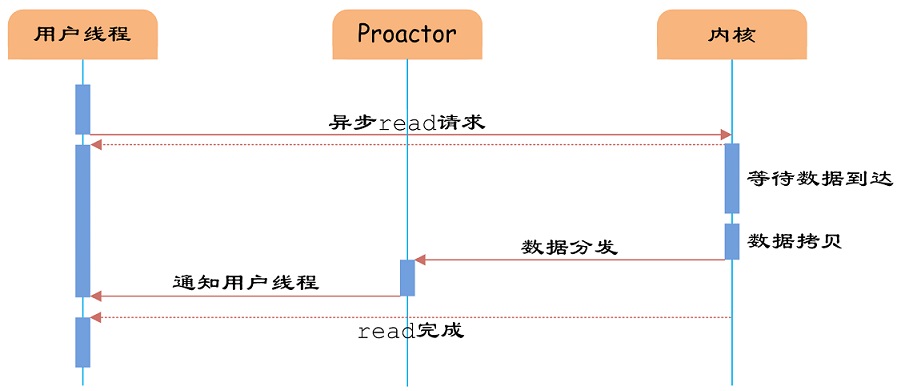
AIO
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程,由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。
异步IO模型使用了Proactor设计模式实现了这一机制。
Java的NIO实现
- NIO新增了许多用于处理输入/输出的类,放到java.nio包下。
- Channel(通道)和Buffer(缓冲)是NIO的两个核心对象,Channel是对传统输入/输出的模拟,Buffer可以理解成一个容器(数组),发送到Channel的数据必须先放到Buffer中。
- NIO采用内存映射的方式来处理输入/输出,效率很高。Channel可以直接将指定文件的部分或全部直接映射成Buffer。
- JDK提供Charset来处理字符集,来进行二进制和字符的编码和解码。
- NIO支持文件锁来阻止多个进程并发修改同一个文件。
- Java7的NIO.2提供了全面的文件IO和基于异步Channel的IO。有Path、Paths、Files核心API。
其他
1、重定向标准输入/输出,Java使用System.in和System.out,分别代表键盘和显示器。提供setErr、setIn、setOut方法来重定向
1 | PrintStream ps = new PrintStream(new FileOutputStream("out.txt")); |
2、JVM读写其他进程的数据,通过Process类提供的三个方法,让程序和子进程进行通信。
1 | Process p =Runtime.getRuntime().exec("javac"); |
3、InetAddress类,获取ip地址相关信息。
1 | InetAddress ip; |
4、对象序列化
- 对象序列化是将对象保存到磁盘中,或者允许在网络中直接传输。将内存中的Java对象转换成平台无关的二进制流,并且将二进制流保存或者通过网络传输。
- 如需要让某个对象支持序列化机制,它的类需要是可序列化的,必须实现Serializable或Externalizable两个接口中的一个。
- 所有在网络上传输的对象都应该是序列化的,比如RMI(远程方法调用)的参数和返回值等。所有需要保存到磁盘里的对象的类也必须序列化。
- 反序列化时需要验证serialVersionUID。系统编译时如果没有定义serialVersionUID,class自动生成一个serialVersionUID作为序列化版本。需要手动定义,不然随着编译版本变化,会导致反序列化失败。
- 实例变量前添加使用transient关键字修饰,可以指定Java序列化时无须理会该实例变量。另外,静态成员也不会被序列化。
- 可重写对象的Serializable接口的writeObject和readObject方法实现自定义序列化。也可重写对象的Externalizable接口的readExternal和writeExternal方法来实现另一个自定义序列化机制。
1 | public class Person implements java.io.Serializable{ |
1 | //序列化 |
九、其他
异常处理
1、使用说明
- try catch finally块,可使用多个catch来区分异常,名为Exception类的catch块要放到最后(先处理小异常,再处理大异常)
- 一个方法被覆盖时,覆盖的方法必须抛出相同的异常或者异常的子类/子集。
- Java7以后,每个catch块可捕获多种类型的异常,使用竖线隔开即可。
- 所有的异常对象,都包含如下几个方法:getMessage获取异常的详细描述字符串、printStackTrace将异常的跟踪栈信息输出、getStackTrace获取异常的跟踪栈信息。
- 使用finally回收资源,如数据库连接、网络连接和磁盘文件等物理资源。Java7以后可以使用try后紧跟的圆括号()来声明、初始化资源,并在程序结束后显式关闭资源。
- 异常链,捕获一个异常,把原始异常信息保存后,然后接着抛出另一个异常,是一种典型的链式处理(23种设计模式之一:责任链模式),可以避免向上暴露太多的实现细节。
- 不要过度使用异常,异常只应该用于处理非正常的情况,不能代替流程控制。不要使用过于庞大的try块,不要忽略捕获到的异常。
2、自定义异常
- 创建自定义异常类,extends Exception。常用的需要定义Runtime异常,则extends RuntimeException。
- 通过throw关键字定义方法,函数内部语句抛出异常(区别于函数声明抛出的throws关键字,函数方法可能抛出异常,给方法的调用者进行解决)
- 调用时使用try catch语句捕获并处理
3、异常类为Throwable类,包含Exception和Error类。
- Error类描述Java运行系统内部错误和资源耗尽错误,一般和虚拟机相关,较为严重,无法恢复或不可捕获,将导致应用程序中断。
- Exception类为非致命性类,可捕捉处理。Exception又分为RuntimeException(unchecked异常,又叫非受控异常,或运行时异常,包括Error也是)和非RunTimeException(Checked异常,又叫受控异常,或编译时异常)。常见的RuntimeException有:NullPointerException、IndexOutOfBoundsException、IllegalArgumentException等。常见的非RuntimeException有IOException、SQLException、InterruptedException等。
- Checked异常要求程序员必须注意该异常,要么显式声明抛出(throws),要么显式捕获并处理它(try catch)。可增强程序的健壮性,但降低了生产率和代码执行效率。
- RuntimeException可以完全不用理会,比抛出Checked异常的灵活性更好。
数据库操作
1、JDBC(Java DataBase Connectivity)
用于执行SQL语句的Java API,是连接数据库和程序的纽带。JDBC用于与数据库建立连接,向数据库发送SQL语句,处理从数据库返回的结果。JDBC不能直接访问数据库,必须依赖数据库厂商提供的JDBC驱动程序,有以下分类:
- JDBC-ODBC桥,依靠ODBC驱动器和数据库通信。需要将ODBC二进制代码加载到客户端。目前较为过时。
- API部分使用Java编写的驱动程序,将客户机API上的JDBC调用转换为Oracle、DB2等DBMS的调用。
- JDBC网络驱动,将JDBC转换为与DBMS无关的网络协议,需要安装中间件。
- 本地协议驱动,纯Java驱动程序,将JDBC调用直接转换为DBMS所使用的网络协议,允许客户机上直接调用DBMS服务器。
2、常用类和接口
Connection接口,代表与数据库的连接。Statement接口,用于在建立连接的基础上向数据库发送SQL语句,包含PreparedStatement和CallableStatement,用来执行动态SQL语句和存储过程的调用。DriverManager类,用于管理数据库中的所有驱动程序。ResultSet接口,用于暂时存放SQL结果集。
连接数据库,需要先加载数据库驱动类。
1 | Class.forName("com.mysql.jdbc.Driver"); |
日志
1、java最早只能System.out,后面有个叫Ceki的巨佬掏出了Log4j,一度成为业内日志标准。后续Log4j成为Apache项目,Ceki也加入了Apache。
2、Sun在1.4版本,util包自带原生日志java.util.logging(JUL)。可实现基础的日志功能,提供Logger、Formatter、Handler三个对象。
此后apache最早提供的日志的门面接口是Jakarta commons logging(JCL),也是最早提供的日志门面接口。
3、之后巨佬Ceki离开了Apache,觉得JCL不好用,就自己撸了SLF4J(Simple logging Facade for Java),取代了JCL。SLF4J是简单日志门面,是日志框架的抽象(slf4j-api.jar包),只提供了统一的日志接口。使用SLF4J的主要目的是不只是功能齐全,方便使用,更重要的是让你的程序独立于任何特定的日志实现。
接口的常用使用方式如下:
1 | private static Logger logger = LoggerFactory.getLogger(ResponseParser.class); |
3、日志系统的实现有以下几类。这几个包可单独使用,但为了拓展,尽量添加slf4j并使用通用API。
- log4j,是apache实现的一个开源日志组件。Java Log的奠基框架,但目前已不推荐使用
- logback,是由log4j的作者Ceki开发,拥有更好的特性,用来取代log4j的一个日志框架,是slf4j的原生实现。已成为Springboot的默认日志。
- Log4j2,是log4j 1.x和logback的改进版,由apache借鉴logback推出,使得日志的吞吐量、性能比log4j提高10倍,支持异步输出,而且配置更加简单灵活。
4、slf4j转向某个实现日志框架,如使用slf4j的API进行编程,底层想使用log4j来进行实际的日志输出,这就是slf4j-log4j12干的事。
- slf4j-jdk14:slf4j到jdk-logging的桥接
- slf4j-log4j12:slf4j到log4j1的桥接
- log4j-slf4j-impl:slf4j到log4j2的桥接
- logback-classic:slf4j到logback的桥接,logback原生实现了slf4j,因此也不需要适配器进行桥接
- slf4j-jcl:slf4j到jcl的桥接
这是我们最常用的方式,那么当slf4j和对应的实现日志框架进行继承时,需要slf4j.api.jar包,以及对应的实现日志框架包外(如log4j需要log4j包,log4j2需要log4j-api和log4j-core包,logback需要logback-core),还需要上述对应的桥接包。
5、某个实际的日志框架转向slf4j,如使用log4j1的API进行编程,但是想最终通过logback来进行输出,所以就需要先将log4j1的日志输出转交给slf4j来输出,slf4j再交给logback来输出。将log4j1的输出转给slf4j,这就是log4j-over-slf4j做的事。
- jul-to-slf4j:jdk-logging到slf4j的桥接
- log4j-over-slf4j(重写上游类的实现)或log4j-to-slf4j(对接上游类的拓展方案):log4j1到slf4j的桥梁。log4j-over-slf4j重写了commons-logging的Log和LogFactory类,做了不同的实现。log4j-to-slf4j 使用OSGI SPI的形式为org.apache.logging.log4j.spi.Provider提供了SLF4J的实现。
- jcl-over-slf4j:用于apache的jcl到slf4j的桥接
6、可通过配置文件logback.xml或log4j2.xml配置,输出到控制台、文件、ELK等。