一、App后台入门
App后台作用
- 远程存储数据
- 消息中转
App后台架构
业务–>问题–>解决方案–>架构
App和后台通信
- http协议or私有协议
- 长连接or短连接
- API定义and通信格式
- 接口风格:REST or SOAP
- App后端differ Web后端
编程语言
- 开发效率
- 擅长业务场景
- 根据业务逻辑来拆分语言
开发周期
需求-原型-UI-交互-研发-测试-上线-迭代
开发模式
Scrum敏捷开发框架(适用场景)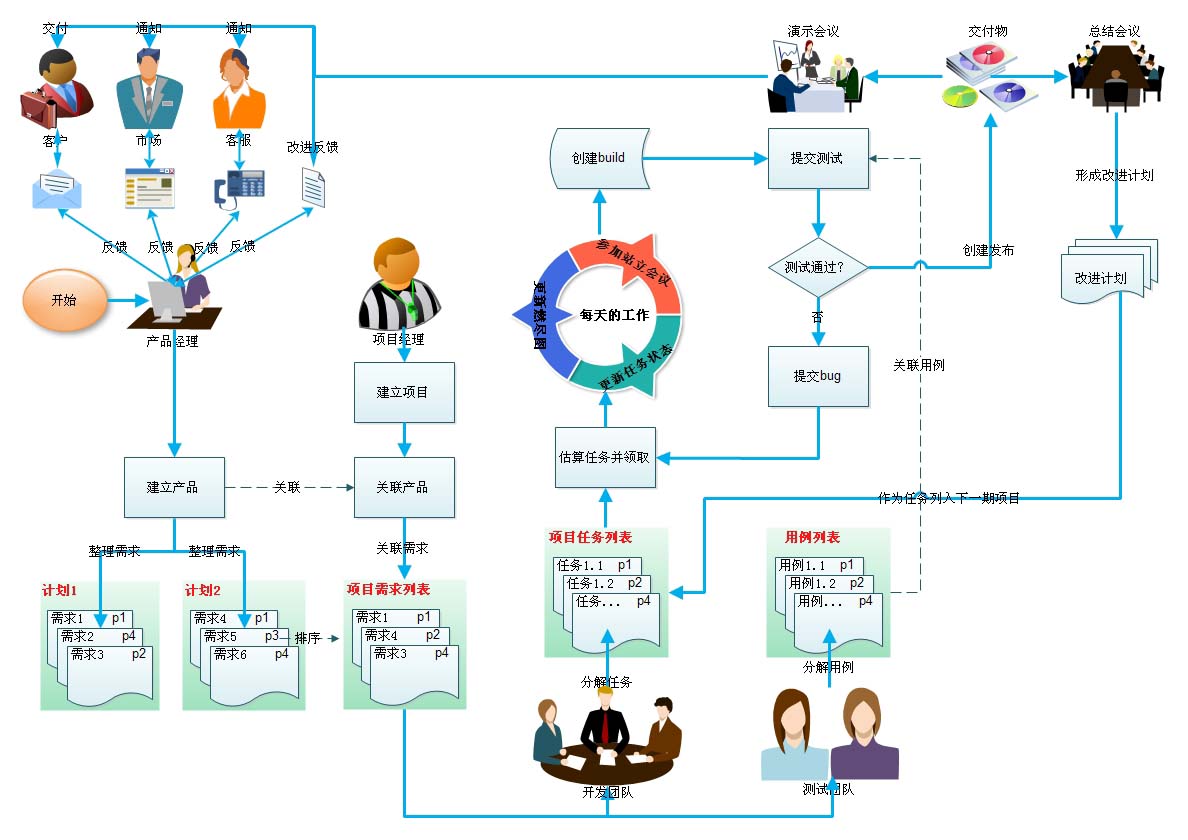
术语中英文对照:
| 英文 | 中文 |
|---|---|
| product | 产品 |
| user story | 需求 |
| sprint | 项目 |
| task | 任务 |
| team | 团队 |
| burndown chart | 燃尽图 |
开发流程
- 1、Sprint会议,完成Sprint Backlog(按每天5小时规划,任务估算超过5小时需细分)。
- 2、日常开发,API先返回假数据,关键性工作采用番茄工作法避免打断。Scrum master负责团队和外部沟通,保证开发效率。
- 3、每日例会:昨天做了哪些?今天要做哪些?有什么工作需要其他同事配合。
- 4、测试和bug修复
- 5、评审会议
- 6、回顾会议:好与不好
- 7、及时反馈、总结,完成PDCA闭环
二、App后台技术基础
从业务逻辑提炼API
1、步骤:业务逻辑思维导图–>功能-业务逻辑思维导图–>基本功能模块关系–>功能模块接口UML–>设计稿API标注–>API文档
2、功能模块划分原则:功能模块和业务逻辑关系,功能模块耦合,一个功能模块可对应多个业务逻辑
api设计要点
- 根据对象设计API
- 返回数据,禁止null值,客户端缺值自动赋予默认值。
- 文档、在线API测试:Swagger-UI
数据库
- Redis:成本高,适用于读写频率高,有消息队列的场景
- MongoDB:大尺寸低价值数据,高伸缩性场景,地理坐标数据等LBS应用,不适用于高度事务性的系统
- MySQL:事务性系统,复杂SQL的问题
分布式服务
- REST:表现层状态转化。无状态,通过GET(Read)、POST(Create)、PUT(Update)、DELETE这4种CRUD,对URI资源进行操作,适用于负载均衡的集群。
- SOAP:简单对象访问协议。有状态,较为成熟,基于xml,安全性有控制
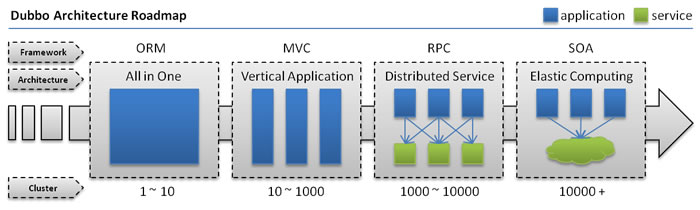
- RPC:远程过程调用协议。跨越OSI应用层,不需要处理socket、http通讯,常见的有Hprose、Dubbo、Dubbox等
搜索技术
分词、倒序索引,常用Lucene、Solr、ElasticSearch
定时任务
Linux下的Crontab,Java下的Quartz,Python下的APScheduler
三、App后台核心技术
App通信安全
- https协议=HTTP+SSL/TLS+TCP+IP+网络传输层,ssl pinning防抓包
- token机制
- 时间戳+URL签名
- AES对称加密和RSA非对称性加密。base64编解码,保障返回的明文数据安全
- 自定义通信协议传输敏感信息
- app加固,防止被反编译
图片视频等
1、图片:不同尺寸app获取,app本地缓存,服务器不同尺寸缓存
2、视频:截图、水印、转码。FFmpeg:A complete,cross-plateform solution to record,convert and stream audio and video.有java调用FFmpeg项目jave。
3、文件系统:涉及分布式存储、图片水印、缩放、剪裁、cdn等,推荐使用云。如自建,推荐的分布式文件存储系统为FastDFS,功能包括文件存储、同步、上传下载和负载均衡。推荐使用GraphicsMagick作为图片处理软件。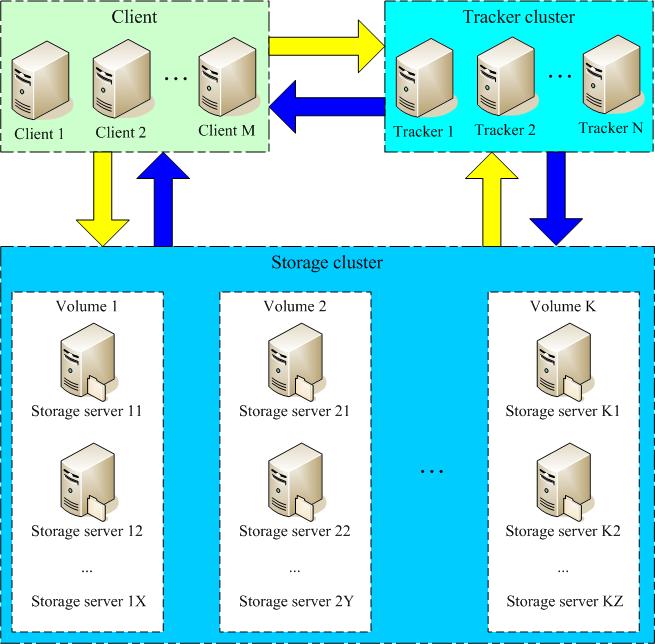
FastDFS由Tracker和Storeage集群两大角色,Client先向Tracker获取上传文件信息,然后向Storage上传具体文件。
4、ELK日志分析平台:目的是将应用服务器集群里的多台服务器的日志进行收集、分析并展示。
Logstash:监控、过滤并收集日志。shipper角色运行在应用服务器,发送日志到indexer。indexer角色接收并索引化事件。
ElasticSearch:一个基于Lucene的分布式索引服务,提供存储搜索。
Kibana一个开源的工具,汇总、分析和搜索数据日志并提供Web页面。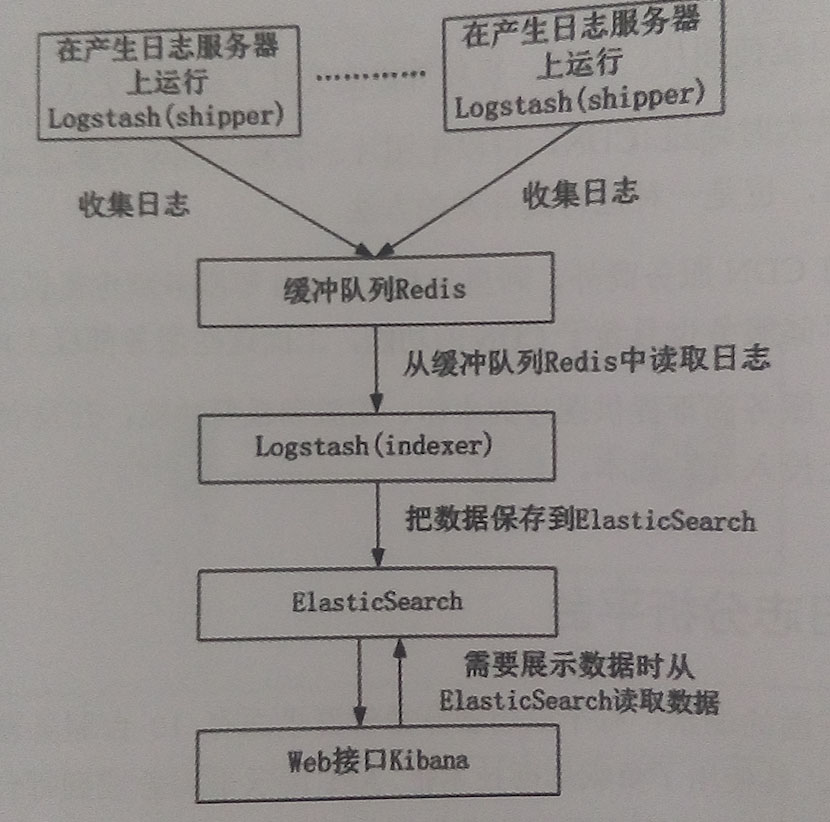
5、Docker:统一开发和部署的轻量级容器,Docker的虚拟化,区别于传统的虚拟化。服务器运行Docker服务,运行多个Docker容器,每个容器相互隔离、独立。
使用Dockerfile,在Docker镜像基础上,安装所需系统和软件,构建相同镜像。
增量更新原理
- 1、目的是配合数据的本地存储
- 2、数据库每条数据,有id、update_time、is_delete值,记录数据的id、最后更新时间、是否删除。api返回size(实际返回数据量)、total(应该返回总数据量)、max(获取的最后一条数据的update_time)
- 3、api请求字段:page(当前页码)、count(每页条数)、since(上次接口获取的最新数据的update_time,如初次为0)、max(当前时间戳)
- 4、当API返回数据size=total,since=max+1,避免重复获取。
- 5、当API返回数据size<total,size= max,避免数据丢失。
- 6、针对返回的id在APP本地数据存在,需过滤。
- 7、如获取的数据is_delete为1,则app本地删除该条数据。
- 8、为减少数据重复的概率,尽量使用毫秒作为update_time。
- 9、可使用id作为更新的标准,这样不会产生重复。但碰到数据更新或删除时,需要插入一条数据,并且注明updateid和deleteid。
四、Linux
基本系统优化
- 开机自启动服务优化,包含0-6的runlevel运行级别。
1 | $ chkconfig [--add] [--del] [--list] [系统服务] |
- 增大文件描述符
常用命令
1、top-系统内存、cpu等资源情况
展示基本信息、任务信息、CPU利用率、内存使用信息、交换区使用信息。cached是存放从磁盘中读取出来的数据,buffers是存放准备写入磁盘的数据。只要Swap分区没有被使用,即使cached和buffers占用了很多内存,也无需担心。可使用top -p 进程id来查看某个进程的资源使用情况。
2、ps-显示进程状态
ps axu | grep 进程名
- a:按用户名和启动时间的顺序来显示进程
- u:显示所有用户的所有进行
- x:显示无控制终端的进程
3、netstat-查看网络相关信息
查看端口是否开启,由哪个端口开启:netstat -lntup
-l:listen,监听的端口。-a:显示所有的Socket,包括正在监听。-n:显示数字格式的地址。-t:监听tcp端口。-u:监听UDP端口。-p:显示建立相关链接的程序名
查看某个端口的连接数:netstat -nat | grep 80
4、lsof-查看某个进程打开的文件
lsof:list open files,命令为:lsof -p 进程id
5、traceroute-跟踪数据到达主机所经路由
五、Nginx
1、工作模型:nginx采用基于epoll网络I/O模型的,效率高于apache(2.4版本前)采用的select模型。
2、进程解析:master process(主进程)和worker process(工作进程)。
3、最大连接数=worker_processes * worker_connetions
4、负载均衡:upstream name{
server 192.168.1.20:80 weight=2;
server 192.168.1.21:80 weight=1;
}
如自建,需保证负载均衡的高可用性,采用Nginx+Keepalived,由Keepalived来做外网ip切换。
5、处理业务逻辑
Nginx添加Lua模块,OpenResty项目使用。
六、Mysql
基本架构
分为服务层(处理连接、安全验证)、核心层(查询、缓存、内置函数、视图、存储过程、触发器)和存储引擎层(数据的存储和提取)。使用Mysql社区版即可。
软件优化
1、MyISAM和InnoDB存储引擎。5.1版本默认MyISAM,5.5和5.6默认InnoDB。InnoDB支持行锁,事务安全,支持外键。
2、使用索引。给合适的列建立索引,使用短索引,使用like查询会导致索引失效。不要滥用索引。如需要搜索大量数据,可使用Sphinx或Coreseek等开源检索引擎。
3、字段尽量设置NOT NULL,使用默认值,保证App客户端处理简便。
硬件优化
1、增加物理内存。 可减少磁盘IO,保证读写数据性能。 MySQL也使用了大量的内存来提高性能。
2、增加应用缓存。本地缓存和分布式缓存(Redis or Memcache)。
3、用固态硬盘代替机械硬盘(最有效手段)。SSD随机读写性能高,因此可把日志和数据分开存储。日志这种顺序读写的还是可以存储在机械硬盘上。涉及到innodb_flush_method和innodb_io_capacity的优化。
4、SSD+SATA混合存储方案:Facebook的FlashCache,将SATA+SSD虚拟成一个带缓存的设备,将SATA上的热数据缓存在SSD上。
架构优化
1、分表。分为水平拆分(将数据保存在不同的表)和垂直拆分(将字段保存在不同的表)。可使用MyISAM的MERGE存储引擎,将分表合成。
2、读写分离。用于主从数据库,主数据库提供写操作,从数据库提供读操作。Mysql主从复制基于主服务器的二进制日志binlog中跟踪随数据库的更新来实现。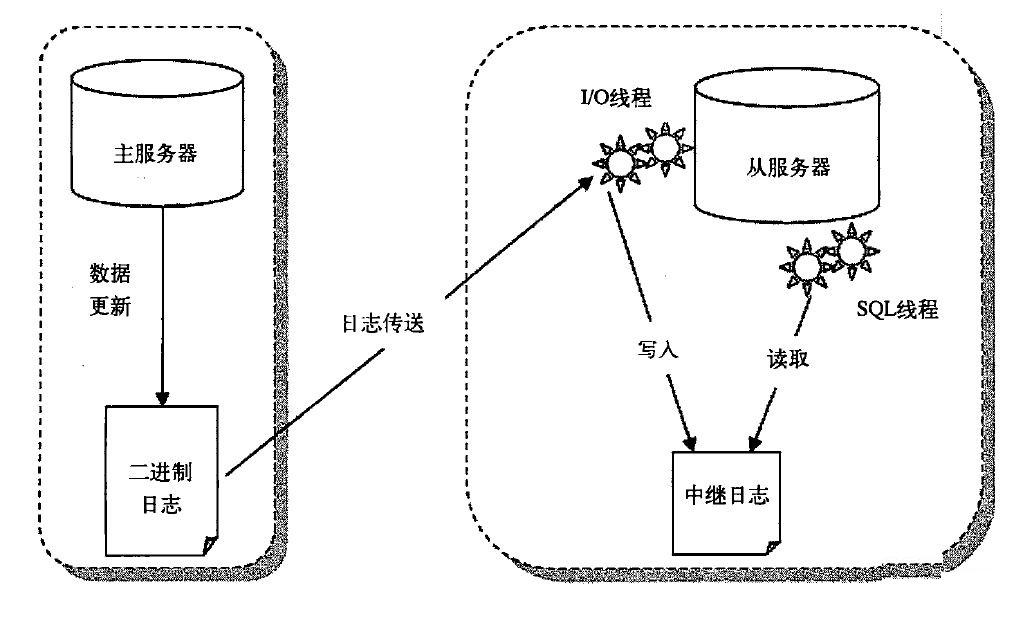
主从复制的延迟解决方案:硬件升级、MySQL5.6以上版本的多线程方案。
3、分库。当分表和读写分离无法满足要求时使用。分布式处理软件:阿里基于Cobar开发的MyCat。将应用服务器的SQL语句按照路由的规则拆解转发到不同的后台数据库,并把结果汇总并返回。
4、SQL慢查询分析。开启满查询分析涉及到的参数:long_query_time,slow_query_log,slow_query_log_file。使用MySQL的explain命令来分析。
5、云数据库。主从热备、弹性拓展、SSD硬盘、监控体系。
##七、架构剖析
聊天APP后台架构。
1、弱网性导致TCP half-open,可使用应用层心跳机制。服务器检查APP连接的方式:第一种每隔一段时间检查所有连接。第二种:每个连接建立一个定时器把连接断开。第三种为时间轮片,例如超时时间为60s,设置60个桶,第一个桶放1秒后要超时的连接,第二个桶放2秒后要超时的连接…… 每秒的定时器都把第一个桶的连接断开。
2、流量敏感。常用的聊天协议:XMPP、MQTT和类ActivitySync(微信)。XMPP协议的开源聊天服务器有Erlang开发的Ejobberd和Java开发的Openfire。
如需要自定义协议,需先解决粘包问题,可参考MySQL协议和Redis协议进行拓展。MySQL协议为一个数据包中,前3字节是数据包长度,第4个字节为数据包的序列号,剩余的字节是数据。Redis协议,*参数个数+$第一个参数字符串字节数+参数+……+第N个参数字节数+参数数据。
丢包问题:传统的基于队列的消息协议,客户端每次都需要有应答,会导致服务器收不到应答,或服务器消息状态出错。于是有了基于版本号的消息协议(陌陌和微信),每个消息有个自增不重复的版本号。服务器向App发送消息后,app将最后收到的消息的版本号返回,服务器将大于该版本号的所有消息按照版本号一次给App。
涉及到图片和声音等文件的聊天数据,只按照纯文本格式进行传输(文件地址)。
3、整体架构。包含连接层、业务层和持久层。
连接层,负责与app保持连接、将消息通过队列转发到逻辑层处理。很少需要重启,会导致大量App掉线。如真需要重启,可发一条消息到App,让其重连时连接别的服务器。集群方案使用动态分配接入点,接入点服务器根据连接服务器负载等计算后,分配一个连接服务器的IP。
业务层,负责处理各种业务逻辑。用户验证、消息路由、统计、数据存储。连接层通过队列方式向业务层传递消息,可保障业务层重启时不丢失消息。
持久层,根据不同业务数据,进行分别存储。
社交App后台架构:类似微博,核心功能是Feed(关注)。
1、基本表结构
热点数据(最近3天)存储在缓存(微博使用Memcached,要求核心缓存命中率达到99%),只有1%请求穿透缓存落到MySQL。有4张基本表,send_content,发送内容表,存储用户发表的内容。
receive_content,接收内容表,用于推模式时村塾用户接收的内容。
followings,关注表,存储用户关注的人。followers,粉丝表,存储用户的粉丝。
2、推拉模式(微博采用拉模式,私密性的微博采用推模式)。
推模式流程:用户发表内容–>写入send_content表–>去follwers表查找粉丝–>将所有粉丝获取的内容分别插入receive_content表–>用户显示feed时,通过receive_content表查询。以空间换时间,推送给多人,延时严重,且浪费存储空间。变更操作成本高,如删除内容需同时删除send_content表和receive_content表。但查询操作简单
拉模式流程:用户发表内容–>写入send_content表–>用户显示feed时,去followings表关注的用户–>通过send_content表查询所有关注的用户的发表内容。拉模式不推送、没有变更成本,但需要大量的聚合运算(可通过缓存策略弥补)。
3、数据库架构演进
分表分库涉及到的自增id,采用全局同意的发id号服务,常见的是time+sequeue涉及,如峰值为100万/s,则前32位精确到表,中间20位表示0-100万的id,最后12位存放其他业务信息。
分表分库,有按hash拆分和按时间拆分两种策略。
hash拆分,例如将发表内容的用户id做hash运算,用id%4来将数据落到4张内容表之一。缺点:特殊用户的查询性能低,冷热数据没法分离读取。
时间拆分,例如将9月份的内容记录在table_201509。
综合拆分,可综合hash拆分和时间拆分。
针对涉及到按时间拆分策略的分表,如需要查询发表内容,可引入二级索引表,避免去所有的分表中都查找一遍。
4、缓存架构演进
分布式缓存,使用余数hash的方案,将某条数据缓存到某台缓存服务器。缺点是,增加、减少缓存服务器时,会造成结果大震荡。当从3台增加到4台,会导致75%数据不能命中。
一致性hash算法,采用分布式哈希(DHT),构造一个长度0-4294967296的圆环,根据计算出的hash值来判断缓存数据是否命中缓服务器。如没有命中,则顺时针在hash环上查找最近的缓存服务器。这个方式,会导致命中率受影响的比例降低到25%。
主从缓存结构,如某台缓存服务器宕机,会造成缓存命中率的大幅降低。采用主从缓存,访问数据时先访问主缓存,如失败再访问从缓存。更新数据时,先对主缓存进行更新,再更新从缓存。
LBS App架构
- 地理坐标:GPS、基站、AGPS、wifi定位。GPS使用WGS-84坐标系统,国内地图需使用GCJ-02对坐标进行加密偏移。
- MySQL提供地理坐标的数据类型和空间函数。
- geohash,可将地理坐标转换为字符串,方便缓存,防止坐标泄漏,值越相似,意味着距离越近。值越长,表示范围越精确。当geohash值长度为6,对应坐标的距离相聚0.61KM。使用LIKE模糊查询即可查找附近所有地点。缺点是like查询很慢,可增加Redis+CoreSeek。将geohash作为Key,id作为value,存储在redis的set集合中–>将坐标的geohash进行Keys方法的匹配获取id,通过CoreSeek继续查找id获取数据。
- MongoDB,性能高,可分布式部署,且支持地理位置查找。查询多边形范围、附近、圆形范围等坐标。使用副本集架构(类似MySQL的主从)保证高可用性。当主从延迟过长时,还可考虑分片架构,将不同地区的位置数据分到不同的分片。
- 新版的redis也支持了地理位置
八、后台架构演进
架构的核心要素
App后台架构的定义:由App后台各个组件的功能描述、相互关系构成的整体系统。
- 高性能,涉及app层、网络传输层、应用服务层、文件服务层、缓存层、数据库层等。app层:手机缓存、增量更新、不同网络环境的不同分辨率图片等。网络传输层:CDN。应用服务层:算法改进、多线程、优化内存、采用Golang、Erlang等高并发场景语言、异步消息队列、服务器集群、分布式缓存软件缓存用户热点请求数据。文件服务器:MogileFS、TFS、FastDFS等分布式文件系统或第三方云存储服务。缓存层。缓存层:Redis、Memcached、云数据库的云缓存服务。数据库层:读写分离、分表、分库。MongoDB的副本集、分片。
- 高可用。7*24小时服务,主要方法是冗余。负载均衡映射到多台应用服务器的集群,并进行健康状态监听。负载均衡要求应用层必须是无状态的。用户的状态信息可以存储在缓存或数据库,供所有应用服务器共同调用。对于数据服务器(数据库、缓存、文件等),需要实时备份。
- 可伸缩。文件数据的可伸缩性、缓存数据的可伸缩性、数据库的可伸缩性(分为NoSQL(例如MongoDB)和关系型数据库)。
- 可拓展。App的快速迭代,导致需求多变。减少模块间的耦合度。可采用消息队列、分布式服务、开放式API。
- 安全性。https、签名、token等,保证数据和接口安全。
架构选型的要点
1、用成熟稳定的开源软件。
| 功能 | 可供选择的开源软件 |
|---|---|
| 项目管理软件 | Mantis、BugFree、禅道 |
| 代码管理软件 | SVN、Git |
| 编程语言 | Java、PHP、Python等 |
| 服务器系统 | CentOS、Ubuntu |
| HTTP/HTTPS服务器 | Nginx、Tomcat、Apache |
| 负载均衡 | Nginx、LVS、HAProxy |
| 邮件服务 | Postfix、Sendmail |
| 消息队列 | RabbitMQ、ZeroMQ、Redis |
| 文件系统 | Fastdfs、mogileFS、TFS |
| Android推送 | Androidpn、gopush |
| IOS推送 | Javapns、Pyapns |
| 地理位置查询LBS | MongoDB |
| 聊天 | Openfire、ejobberd |
| 监控 | ngiOS、zabbix |
| 缓存 | Memcache、Redis |
| 关系型数据库 | MySQL、MariaDB、PostgreSQL |
| NoSQL数据库 | Redis、MongoDB、Cassandra |
| 搜索 | Coreseek、Solr、ElasticSearch |
| 图片处理 | GraphicsMagick、ImageMagick |
| 分布式访问服务 | dubbo、dubbox |
2、优先选择云服务。
| 功能 | 可供选择的云服务 |
|---|---|
| 项目管理工具 | Teambition、Tower |
| 代码托管平台 | GitHub、Gitlab、Bitbucket、CSDN CODE、Coding |
| 负载均衡 | 阿里云SLB、腾讯云CLB |
| 邮件服务 | SendCloud、MailGun |
| 消息队列 | 阿里云MNS、腾讯云CMQ |
| 文件系统、图片处理 | 七牛云、阿里云对象存储OSS、腾讯云对象存储COS |
| Android推送 | 极光、个推、百度推送 |
| IOS推送 | 极光、个推、百度推送 |
| 聊天 | 融云、环信 |
| 监控 | 监控宝、云服务器自带的监控服务 |
| 缓存 | 阿里云缓存服务、腾讯云弹性缓存 |
| 关系型数据库 | 阿里云RDS、腾讯云CDB |
| NoSQL数据库 | 阿里云NoSQL产品、腾讯云NoSQL产品 |
| 搜索 | 阿里云开放搜索、腾讯云搜TCS |
| 分布式访问服务 | 阿里云EDAS |
| 防火墙 | 阿里云云盾、腾讯云安全 |
| 短信发送 | shareSDK、bmob、Luosimao |
| 社交登录分享 | shareSDK |
3、架构的演进
- 单机部署,App后台极简化架构。有负载均衡,使用Redis缓存+消息队列。
- 分布式部署,新增ssh专用通道,保证运维需要。使用负载均衡转发到集群。保证Redis缓存扩容和足够的QPS。主从数据库,分表、分库。
- 服务化,多模块、功能重复、跨语言、维护成本高。把业务分拆成不同的模块,各个模块间独立调用。数据库和缓存集群按照业务继续分拆。
4、架构的特点
- 每个App的后台架构不会完全一样。
- 架构的演进,是由业务驱动的。
- 架构不是为了炫耀技术。
- 尽量使用成熟可靠的云服务和开源软件,自身只专注于业务逻辑。