一、爬虫介绍
爬虫库
- urllib/urllib3,python自带,有短板
- requests,用来请求网站获取网页数据。
- Beautiful,用来解析html和xml,提取数据。
性能对比
html解析性能对比,如结构简单且避免额外依赖可选择正则,爬取数据量较少可使用BeautifulSoup,当数据量大时Lxml是最好的选择。
| 爬取方法 | 性能 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则表达式 | 快 | 困难 | 简单(内置模块) |
| BeautifulSoup | 慢 | 简单 | 简单 |
| Lxml | 快 | 简单 | 相对困难 |
二、requests
安装
- pip3 install requests
使用
1 | import requests |
三、BeautifulSoup
安装导入
1 | $ pip3 install bs4 |
1 | from bs4 import BeautifulSoup |
解析器对比
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup( markup, “html.parser”) | Python的内置标准库,执行速度适中,文档容错能力强 | Python 2.7.3 or 3.2.2)前的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup( markup, “lxml”) | 速度快,文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup( markup, “xml”) | 速度快,唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup( markup, “html5lib”) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
BeautifulSoup对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag对象,与html原生tag相同。tag有名称(Name),属性(Attributes)。
- NavigableString对象,可以遍历的字符串。
- BeautifulSoup对象,表示一个文档的全部内容
- Comment对象,是一个特殊类型的NavigableString对象,注释及特殊字符串。
下列代码可参考『ipynb文档传送门』
1 | # 通过文件创建BeautifulSoup对象,默认使用lxml作为解析器,推荐 |
1 | html_doc = """ |
1 | # 通过字符串创建BeautifulSoup对象 |
1 | # 查看BeautifulSoup对象的name |
通过BeautifulSoup对象获取Tag对象、NavigableString对象、Comment对象
1 | # 获取Tag对象 |
1 | # 可以循环调用,当循环调用时,其实可以把BeautifulSoup对象当做Tag对象 |
1 | # 查看对象类别 |
1 | # 获取NavigableString对象 |
1 | # 查看对象类别 |
1 | # 获取Comment对象 |
1 | # 查看对象类别 |
Tag对象操作
1 | tag=soup.b |
1 | # 获取Tag对象的某个属性 |
1 | # 和上面等价 |
1 | # 获取Tag对象的所有属性 |
1 | # 删除Tag对象的某个属性 |
1 | # 修改Tag对象的某个属性 |
1 | # 查找匹配某个属性的标签 |
1 | # class是python关键字,因此以class_代替 |
1 | for link in soup.findAll('a'): |
遍历文档树
1、子节点
1 | # 一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点 |
1 | # Tag的contents属性可以将tag的子节点以列表的方式输出 |
1 | # 查看列表长度 |
1 | # Tag的children生成器,可以对tag的子节点进行循环 |
1 | for child in body_tag.children: |
1 | # .contents 和 .children 属性仅包含tag的直接子节点,descendants会递归所有子孙节点 |
1 | title_tag=soup.head |
1 | # 如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点 |
1 | # 如有多个,可以使用strings得到所有NavigableString子节点 |
2、父节点
1 | title_tag = soup.title |
1 | # 获取tag的父节点 |
1 | # 父节点可能是Tag对象(上一行),可能是BeautifulSoup对象(本行),也有可能是None(下一行) |
1 | print(soup.parent) |
1 | # 通过元素的 .parents 属性可以递归得到元素的所有父辈节点 |
3、兄弟节点
1 | b_tag=soup.b |
1 | # 有换行符的缘故 |
1 | # 下一个的下一个兄弟节点 |
1 | # 上一个的上一个兄弟节点 |
1 | # 通过 .next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出 |
4、回退和前进
1 | title_tag |
1 | # 没有上个兄弟节点,因此为空 |
1 | # 上一个解析的对象(本行是Tag对象,下一行是字符串) |
1 | # 下一个解析的对象 |
1 | for element in title_tag.previous_elements: |
搜索文档树
1、过滤器
find_all需要传入过滤器,过滤器可以被用在tag的name中,节点的属性中,字符串中或他们的混合中
1 | # 1、最简单的过滤器是字符串 |
1 | # 2、过滤器是正则表达式 |
1 | # 查找文档中所有的包含t的标签 |
1 | # 3、过滤器是列表 |
1 | # 4、过滤器可以是True,可以匹配任何值,查找到所有的tag,但是不会返回字符串节点 |
1 | # 5、过滤器可以是函数,查看包含 class 和 id 属性的Tag |
2、find_all函数格式:
find_all( name , attrs , recursive , text , **kwargs )
1 | # 1、name参数 |
1 | # 2、kwargs参数 |
1 | # 也可以使用正则 |
1 | # 可以混用,name参数和是多个kwargs参数的组合 |
1 | # 查找有id属性的Tag |
1 | # 按CSS查询 |
1 | soup.find_all(class_=re.compile("ist")) |
1 | def has_six_characters(css_class): |
1 | # 3、text参数,可以搜索文档中的字符串内容 |
1 | # 4、limit参数,限制返回的个数 |
1 | # 5、recursive参数,默认为非直接子节点。可指定为False查找直接子节点 |
1 | # p节点下有a直接子节点 |
1 | soup.find_all("a") |
1 | # 等价于上一行 |
3、find函数格式
find( name , attrs , recursive , text , **kwargs )
1 | # 和find_all的limit=1等同 |
4、
1 | find_next_siblings() 和 find_next_sibling()格式 |
这4个方法通过 .previous_siblings 和.next_siblings属性对tag的前后解析
1 | first_link = soup.a |
1 | first_link.find_next_siblings("a") |
1 | first_link.find_next_sibling("a") |
5、
1 | find_all_next() 和 find_next()格式 |
这4个方法通过 .previous_elements 和.next_elements 属性对tag进行前后解析
1 | first_link = soup.a |
1 | first_link.find_all_previous("title") |
6、CSS选择器
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用CSS选择器的语法找到tag
1 | # 通过title直接查找 |
1 | # 通过tag标签逐层查找 |
1 | # 找到某个tag标签下的直接子标签 |
1 | # 找到兄弟节点标签 |
1 | soup.select("#link1 + .sister") |
1 | # 通过CSS的类名查找 |
1 | # 通过tag的id查找 |
1 | # 通过属性的值来查找 |
输出
1 | # 格式化输出 |
1 | # 压缩输出 |
四、实战项目
链家
使用BeautifulSoup
1 | import requests |
酷狗
使用BeautifulSoup
1 | import requests |
小猪短租
使用BeautifulSoup
1 | import requests |
糗事百科
使用re正则匹配
1 | import requests |
豆瓣
使用lxml和csv,注意Xpath语法
1 | from lxml import etree |
起点
使用lxml和xlwt
1 | from lxml import etree |
五、多进程爬虫
在糗事百科demo基础上,增加多进程爬虫测试。效果如下:
1 |
|
运行结果如下,多进程运行时,任务管理器有多个Python进程同时运行:
1 | 串行爬虫: 5.448936939239502 |
六、selenium
介绍
Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样。Selenium也是一个强大的网络数据采集工具,其可以让浏览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据,避免进行逆向工程。
phantomjs就建议不要装了。第一费劲,第二selenium新版已不推荐。还是使用chrome好了。
chrome需要下载『chromedriver』 ,需要下载对应的版本。不一定非要放到/usr/bin,放到这个路径需要做权限设置,十分麻烦,可随意放个地方,然后
1 | $ open ~/.bash_profile |
示例
1 | from selenium import webdriver |
七、爬虫框架
Scrapy
Scrapy是一个用 Python 写的 Crawler Framework ,简单轻巧,并且非常方便。Scrapy 使用 Twisted 这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示
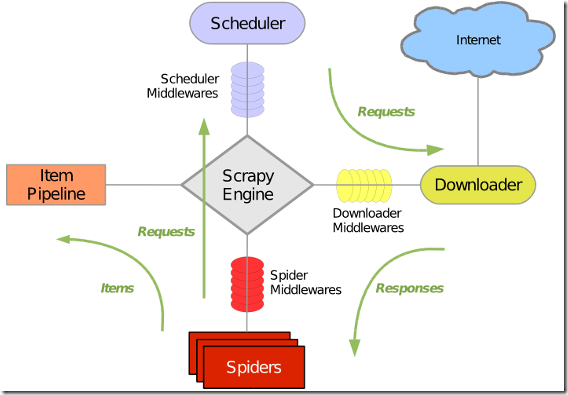
绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
1 | $ pip3 install scrapy |
创建好的工程目录结构如下:
- spiders/spider.py,Spider蜘蛛
- items.py,对要爬取数据的模型定义
- pipelines.py,对爬虫数据的处理
- middlewares.py,爬虫中间件
- settings.py,对爬虫的配置,请求header、设置pipelines等
实例
以爬取简书推荐作者页面为例:
1、items.py
1 | from scrapy.item import Item,Field |
2、setting.py
1 | BOT_NAME = 'author' |
3、pipelines.py
1 | import pymongo |
4、authorspider.py
1 | from scrapy.spiders import CrawlSpider |
5、main.py
1 | from scrapy import cmdline |
相关代码