一、Zookeeper
定义
Service Registry(服务注册表)是微服务架构的核心,提供服务注册功能,为服务发现提供支持。开源服务注册组件有Zookeeper『官网传送门』,netflix的Eureka,COreOS的Etcd,hashiCorp的Consul等。
Zookeeper是服务注册表的最佳解决方案之一,由Yahoo使用Java开发,原是Hadoop项目的子项目,基于Google的Chubby的开源实现,设计目标是将那些复杂且容易出错的分布式一致性服务加以封装,构成一个高效可靠的服务。
Zookeeper是一个经典的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据发布与订阅、负载均衡、命名服务、分布式协调和通知、集群管理、领导选举、分布式锁和队列等功能。
Zookeeper一般以集群的方式对外提供服务,包括五大特性
- 顺序性,同一个客户端的请求确保“先进先出”
- 原子性,整个集群中所有机器要么都成功的处理了某一个请求,要么就都没有处理。
- 单一性,无论客户端连接到哪台ZooKeeper,客户端看到的服务端数据模型都是一致的。(ZooKeeper服务器之间会高效的同步)
- 可靠性,分布式,leader有故障后,别的节点可自动接管
- 实时性
节点类型
ZooKeeper拥有一个树状的内存模型,将这些目录与文件统称为ZNode,每个ZNode有对应的路径和包含的数据。客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。ZNode节点类型:
- PERSISTENT,持久化节点
- PERSISTENT_SEQUENTIAL,顺序自动编号持久化节点,这种节点会根据当前已存在的节点数自动加1。
- EPHEMERAL,临时节点,客户端session超时这类节点就会被自动删除
- EPHEMERAL_SEQUENTIAL,临时自动编号节点
集群结构:
ZooKeeper没有采用经典的分布式一致性协议Paxos,而是参考设计了一款轻量级协议Zab(ZooKeeper Atomic Broadcast),该协议分为两个阶段,领导选举和原子广播。
领导选举:当ZooKeeper以集群启动后,会自动选举一台节点为Leader,其他为Follower。当Leader出现故障后重新选举。
原子广播:将同步Leader节点和Follower节点的数据,确保同步。
ZooKeeper服务器端
采用docker,如需要详细,可参考另一篇专门介绍docker的文章。
1 | $ docker run --name zookeeper1 --restart always -d -p 2181:2181 zookeeper |
/conf/zoo.cfg配置文件包含内容:
1 | $ cat zoo.cfg |
ZooKeeper客户端
1、命令行方式:
1 | $ bin/zkCli.sh #命令行客户端 |
2、Java客户端:
官方提供Java客户端API,maven配置如下:
1 | <dependency> |
创建对象:ZooKeeper(String connectString,int sessionTimeout,Watcher watcher)。有getChildren(),exists(),create(),getData(),setData(),delete()等节点操作方法,和客户端命令作用一致。
3、Node.js客户端
非官方客户端node-zookeeper-client,使用NPM安装,同样可使用getChildren(),exists(),create(),getData(),setData(),remove()等函数操作节点。
1 | $ npm install node-zookeeper-client |
1 | #zookeeper.js |
服务注册组件java实现
1、设计服务注册表数据结构
如我们在192.168.1.1机的8080端口发布service1,8081端口发布service2,在192.168.1.2机的8080端口发布了service1,所应展示的树状模型如下:
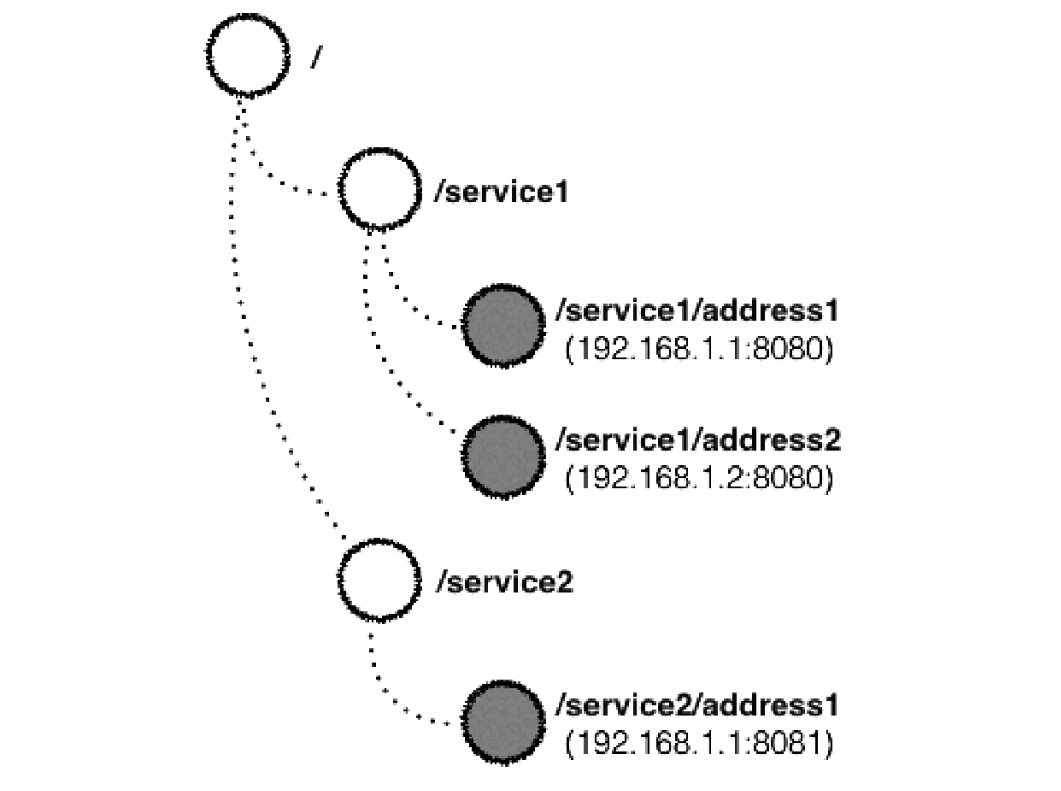
/为根节点,/service为服务节点,/service/address为地址节点,根节点和服务节点是持久的,地址节点是临时且顺序的。
当某个服务出现故障,Zookeeper会与该服务所在的客户端进行心跳检测,并将对应的地址节点从模型移除。
相关java代码参考:
1 | #看到有注册 |