一、Spring Boot Actuator应用监控
SpringBoot有一个Actuator的插件,用来输出应用程序的端点(Endpoint),包括健康检查(/health)、运行指标(/metrics)、线程信息(/dump)等。
1、pom.xml依赖
1 | <dependency> |
2、配置文件,暴露所有Endpoints
1 | management.endpoints.web.exposure.include=* |
3、以Spring Boot 2.x版本为例,访问路径/actuator可查看所有endpoints的路径。
| 端点路径 | 应用程序说明 |
|---|---|
| /actuator/info | 基本信息 |
| /actuator/health | 健康状况 |
| /actuator/metrics | 运行指标 |
| /actuator/env | 环境变量 |
| /actuator/loggers | 日志级别配置 |
| /actuator/dump | 线程信息 |
| /actuator/httptrace | 请求调用轨迹信息 |
但是以上信息都是以数据形式直接访问,需要通过用户界面的方式呈现数据。
二、Spring Boot Admin开源的应用监控系统
Spring Boot Admin包含了服务端和客户端。功能包括
- 查看健康状态
- 查看JVM和内存指标
- 查看计数器与计量表指标
- 查看数据源指标
- 查看缓存指标
- 查看系统构建信息
- 查看并下载日志文件
- 查看JVM系统属性与环境变量
- 查看线程堆栈信息
- 查看调用轨迹信息
- 查看状态变更日志
- 修改Logback日志级别管理
- 修改JMX参数
- 下载JVM堆内存文件
- 通知状态变更(邮件等)
admin端
1、pom.xml依赖
1 | <dependency> |
2、应用主类中使用@EnableAdminServer注解
3、浏览器访问 http://localhost:8080 可查看到2.0新的vue页面。目前Application为0,需要添加client。
client端
1、pom.xml依赖
1 | <dependency> |
2、配置文件
1 | server.port=8081 |
3、再次访问admin端 http://localhost:8080 可查看相关页面。
Applications页面: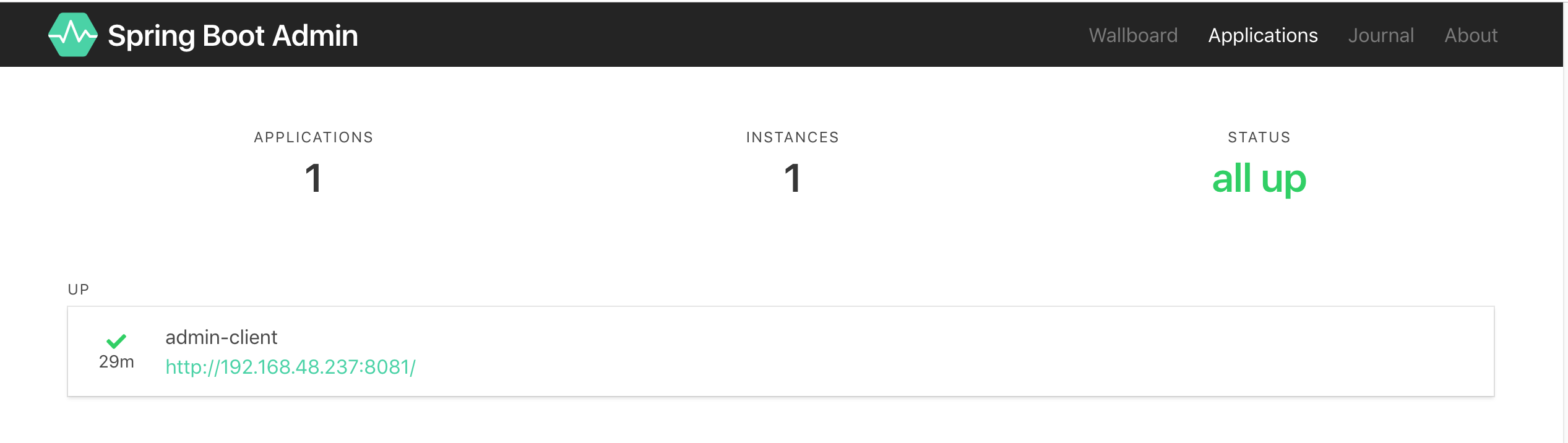
Journal页面: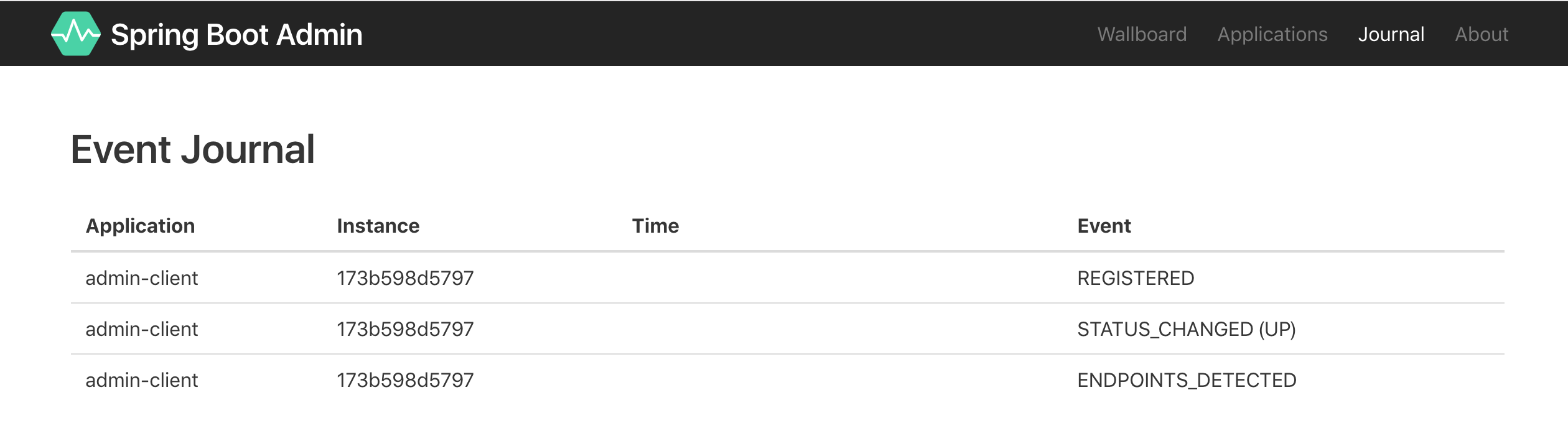
Wallboard各指标页面: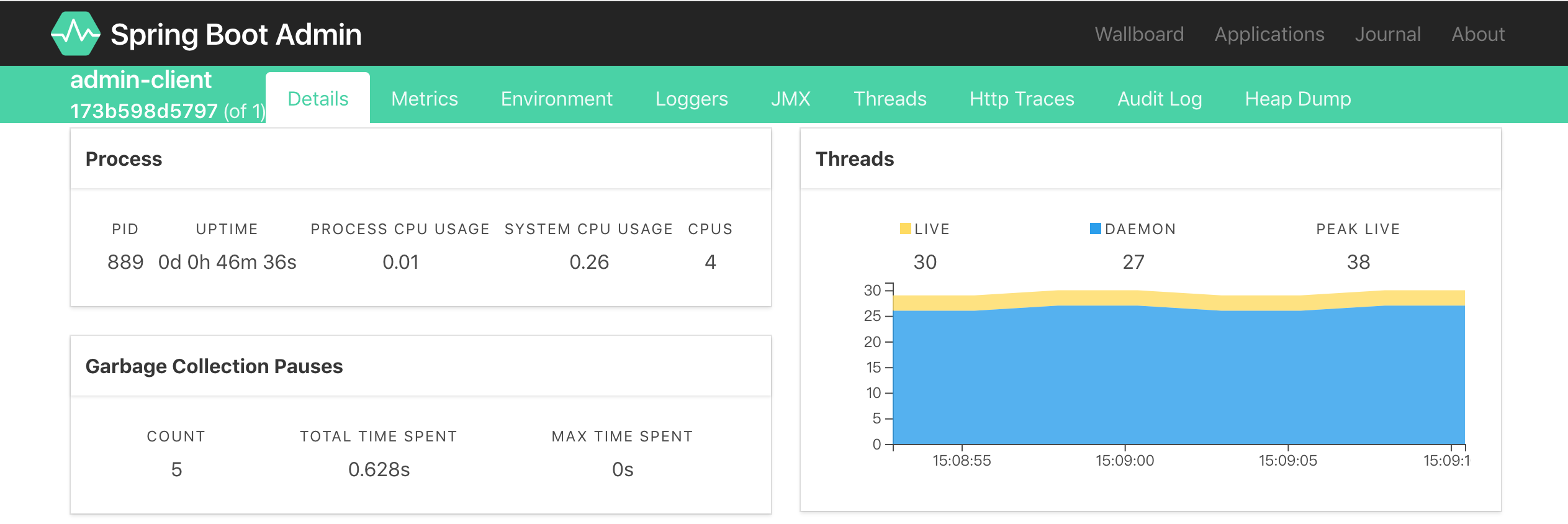

以上可拓展登录安全校验,或基于Eureka来实现自动注册。
三、系统监控中心
以上两章为微服务内部运行状况的监控,本章为微服务所在操作系统的监控,均使用开源技术搭建,分为以下3个部分:
- 时序数据收集系统,不断收集Docker容器随时间变化的数据,即时序数据,包含CPU、内存、网络、磁盘等使用情况,如cAdvisor。
- 时序数据存储系统,将时序数据存入时序数据库,如InfluxDB。
- 时序数据分析系统,通过图表方式展示并分析时序数据,如Grafana。
时序数据存储系统 InfluxDB
InfluxDB是一种Time Series Database,是InfluxData公司的产品,用来存储时序的大数据。
Docker运行命令如下。
1 | #运行influxdb |
另外,InfluxDB提供命令行客户端,和REST API(默认使用8086端口,有Java和Go等语言),以及集群企业版本InfluxEnterprise。
时序数据收集系统 cAdvisor
Google推出的基于Go的开源产品,用于分析Docker容器在运行中的资源使用与性能特征。使用Docker容器运行后即可监控当前宿主机中所有Docker容器的运行状况。
Docker运行命令如下,当宿主机为centOS操作系统时会有所不同,详情见官方文档。
1 | $ sudo docker run \ |
相关统计如下图: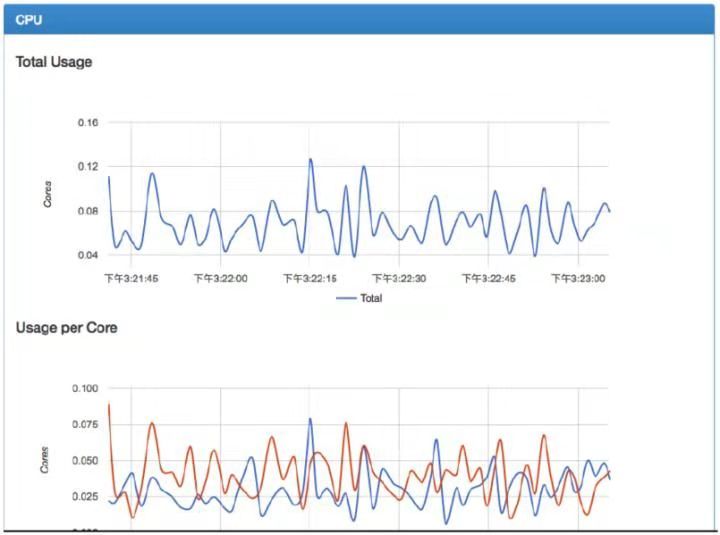
cAdvisor还提供REST API。
缺点:
- 只能监控当前宿主机,无法监控远程。需要每台机器都部署
- 只能监控当前一段时间内的时序数据,如何长期存储
时序数据分析系统 Grafana
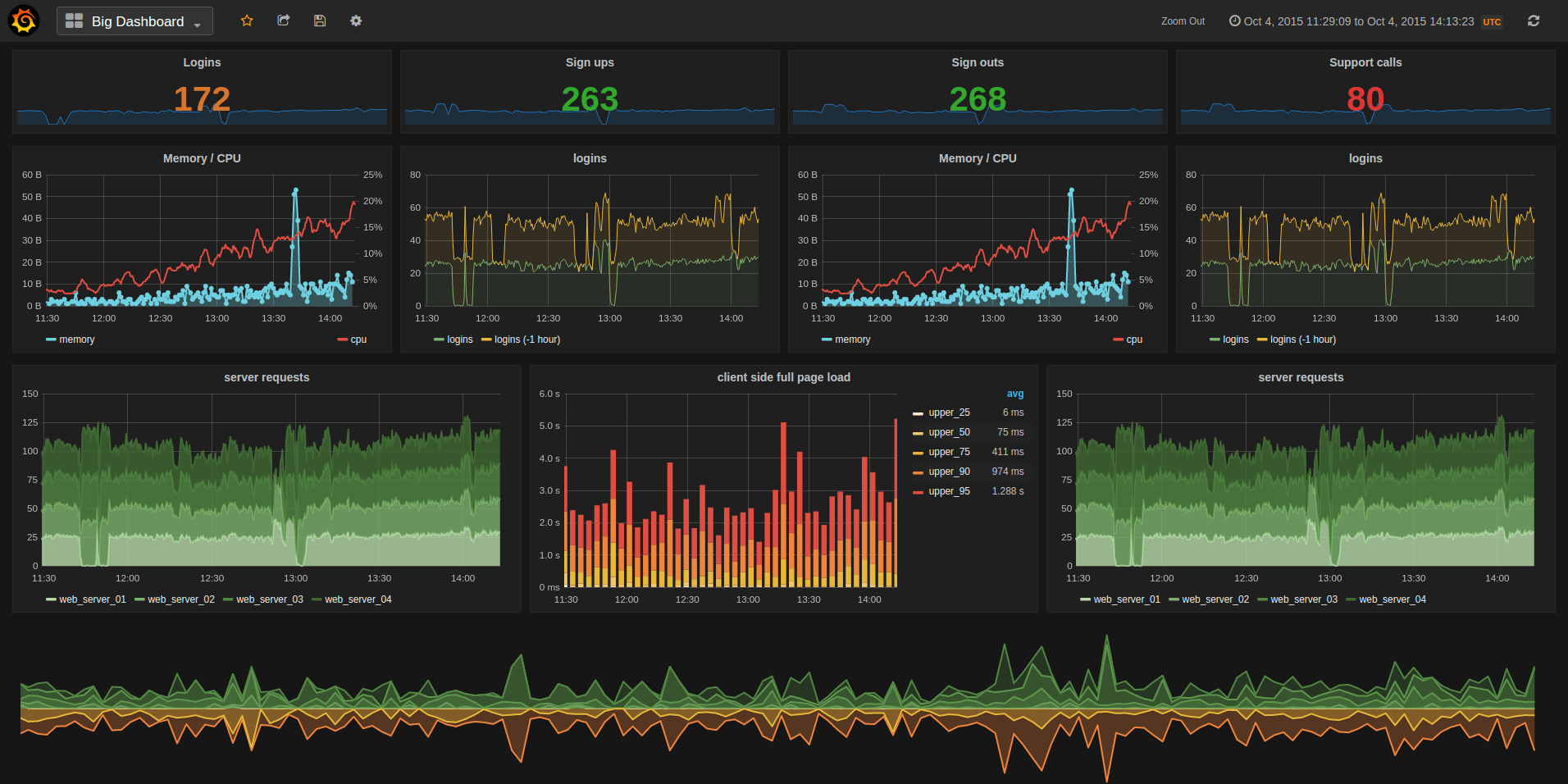
Docker运行命令如下。
1 | #运行grafana |
访问 http://loacalhost:3000 到达登录界面。
三者集成
- 1、启动InfluxDB,暴露端口8086,创建库表。
- 2、启动aAdvisor,需连接InfluxDB容器,并传入influxdb初始化参数
- 3、启动Grafana,需连接InfluxDB容器,并在Dashboard界面手工添加Grafana数据源。
四、调用追踪中心-Zipkin
zipkin介绍
Zipkin是Twitter公司开源的一款调用追踪中心,用来收集分布式系统每个组件所花费的调用时长,并通过图形化界面展示整个调用链依赖关系,解决微服务架构中的延迟问题。
Zipkin参照Google的Dapper论文设计思想来开发。
Dapper的几个概念:
- Span,基本工作单元,调用一个组件所经历的一段过程,从请求组件开始到组件响应为止。
- Trace,追踪链路,指的客户端发出请求,知道完成整个内部调用的全部过程,可能包含多个Span。
- Reporter,将Span和Trace产生的追踪数据需要从客户端推送到zipkin的collector,官网包含了大量实现Reporter的代码库,可通过HTTP、Kafka(Apache开源)和Scribe(Facebook开源)等进行传输。
- Annotation,注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息:1、cs - ClientStart,表示客户端发起请求。2、sr - Server Receive,表示服务端收到请求。3、ss - Server Send,表示服务端完成处理,并将结果发送给客户端。4、cr - Client Received,表示客户端获取到服务端返回信息。
- Collector,会对一个到来的被trace的数据(span)进行验证、存储并设置索引。
- Storage,存储,zipkin默认的存储方式为in-memory,即不会进行持久化操作。如果想进行收集数据的持久化,可以存储数据在Cassandra、ElasticSearch和MySQL中。
- API,提供了一个用于查找和检索跟踪的简单JSON API,此API的主要使用者是WebUI。
- WebUI,展示页面。
所有组件的架构流程图如下:

zipkin运行
1 | #方法1,jar包启动 |
访问地址 http://localhost:9411/ 即可访问。
五、Spring Boot和zipkin整合
为实现zipkin,需要几个的module。
- zipkin-server,作为zipkin的server端和管理后台
- zipkin-service-1,zipkin-service-2,zipkin-service-3。service1调用service2,service2调用service3。
zipkin-server
1、pom依赖
1 | <dependency> |
2、yml配置文件,使用默认端口9411。需要配置management.metrics.web.server.auto-time-requests参数,不然访问后台页面时会报错 “UT005023 Exception handling request to /zipkin/index.html”。
1 | server: |
3、在入口主类增加注解@EnableZipkinServer。
4、启动后访问 http://localhost:9411 即可看到后台页面。目前为空。需要后续调用。
zipkin-service1,zipkin-service2,zipkin-service3
这3个service的依赖和配置基本一致。
1、pom依赖
1 | <dependency> |
2、yml配置,3个service项目的server.port分别是8081,8082,8083。spring.application.name分别是service1,service2,service3。
1 | server: |
3、在入口主类增加@Bean,用于service间http调用。
1 | @Bean |
4、3个service各自新建Controller,如下。
1 | //service1的controller |
5、依次启动zipkin-server,zipkin-server3,zipkin-server2,zipkin-server1,访问 http://localhost:8081/service1 可依次完成service3、service2、service1的调用。
6、再次访问 http://localhost:9411 查看后台页面。有记录如下:
显示了每次Trace的调用概要信息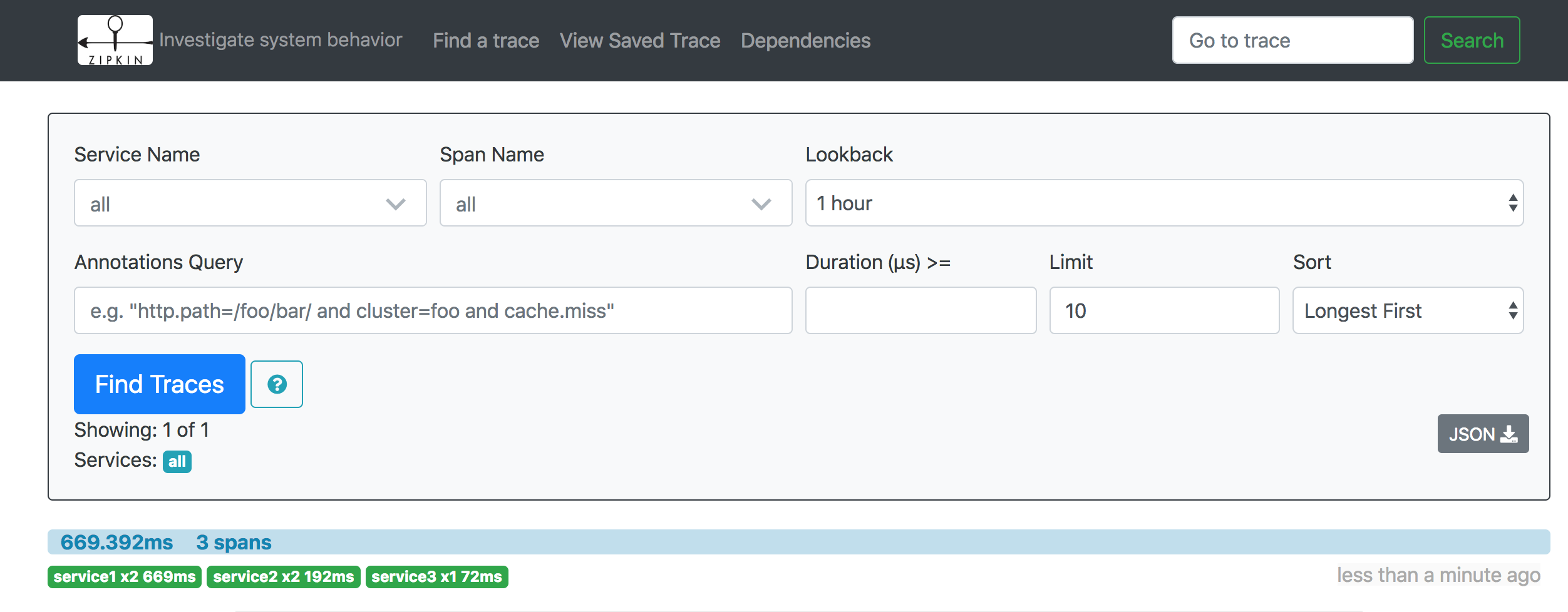
以本条Trace为例,包含了Total Spans数,持续时间(Duration),调用涉及的服务数(Services),调用深度(Depth),下方有调用链追踪图。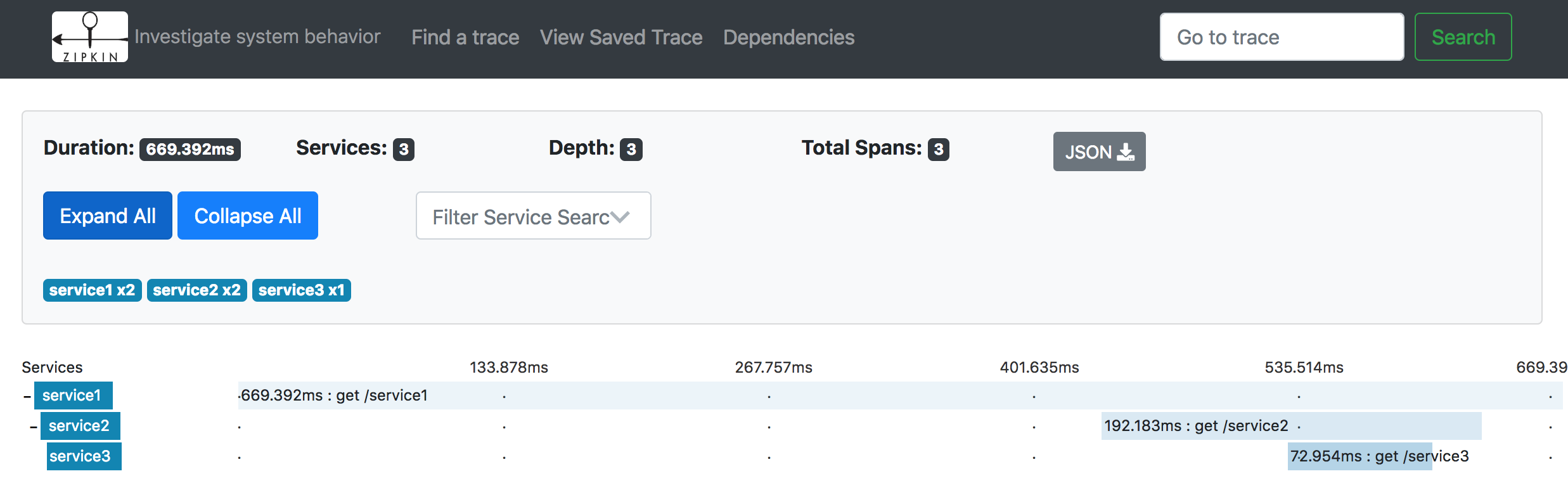
查看调用的依赖关系:
后续改进
- Zipkin Server注册到Eureka,实现服务发现。
- 使用消息中间件如RabbitMQ等,收集数据。实现Server和Client端解耦。
- 使用Elasticsearch存储跟踪数据,需借助zipkin-dependencies组件。
相关代码