一、k-近邻
k近邻法(k-nearest neighbor,k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的算法的描述为:
- 计算测试数据与各个训练数据之间的距离(欧式距离或曼哈顿距离);
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
优点:
- 精度高
- 对异常值不敏感
- 无数据输入假定
缺点:
- 计算复杂度高
- 空间复杂度高
二、分类示例1-电影分类
问题背景
根据电影的打斗镜头和接吻镜头,来判定电影类型
| 电影 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 电影1 | 3 | 104 | 爱情片 |
| 电影2 | 2 | 100 | 爱情片 |
| 电影3 | 1 | 81 | 爱情片 |
| 电影4 | 101 | 10 | 动作片 |
| 电影5 | 99 | 5 | 动作片 |
| 电影6 | 98 | 2 | 动作片 |
| ? | 18 | 90 | ? |
采用欧式距离(可理解为直线距离)计算未知电影和已知的距离,当前示例有2个特征,为2维空间,通过计算可得:
| 电影 | 与未知电影的距离 |
|---|---|
| 电影1 | 20.5 |
| 电影2 | 18.7 |
| 电影3 | 19.2 |
| 电影4 | 115.3 |
| 电影5 | 117.4 |
| 电影6 | 118.9 |
假定k=3,则3个靠近的电影依次是电影2、电影3和电影1,这三部电影都是爱情片,则我们判定未知电影是爱情片。
python实现
主要算法实现:kNN.py
1 | ''' |
测试数据集分类
1 | import kNN |
三、分类示例2-男士魅力分类
收集数据
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 没有魅力的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingDataSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所消耗时间百分比
- 每周消费的冰淇淋公升数
准备数据
1 | ''' |
调用方法将文件转成矩阵
1 | datingDataMat,datingLabels = kNN.file2matrix('datingDataSet.txt') |
分析数据
使用matplotlib进行数据可视化,将3个特征两两进行分析:
1 | import kNN |
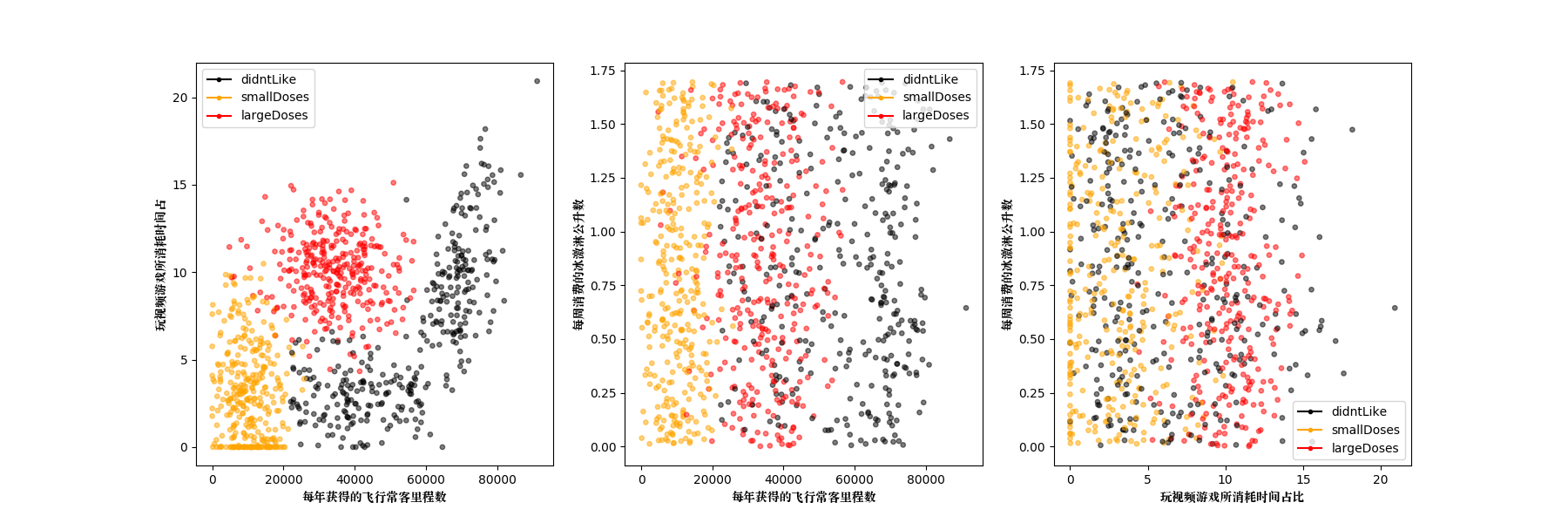
通过数据可以很直观的发现规律,比如海伦喜欢的人的特征包括:飞行常客中等(不能太闲和太忙),要玩视频游戏多的。至于是否吃冰淇淋看起来不重要。
准备数据:数据归一化
当计算本例的距离时,会发现飞行常客里程数值过大,如果三个特征同样重要,则需要归一化,保证权重相同。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
newValue = (oldValue - min) / (max - min)
其中min和max分别是数据集中的最小特征值和最大特征值。
1 | """ |
测试算法:验证分类器
1 | def datingClassTest(): |
得到的错误率为5%,可调整k值和测试数据比例,得到不同的错误率。
1 | 错误率: 0.050000 |
使用算法
1 | def classifyMan(man): |
使用算法进行分类:
1 | #使用kNN算法分类 |
结果如下:
1 | man1 is :魅力一般 |
四、分类示例3-手写数字识别
trainingDigits文件夹为训练集,testDigits文件夹为测试集。
1 | import kNN |
学习结果如下:
1 | ... |