一、线性回归
回归
回归是监督学习的一个重要问题,回归用于预测输入变量和输出变量之间的关系,目的是预测数值型的目标值。
回归模型(回归方程)是表示输入变量到输出变量之间映射的函数。
回归问题的学习等价于函数拟合:使用一条函数曲线使其很好的拟合已知函数且很好的预测未知数据。
回归问题分为模型的学习和预测两个过程。基于给定的训练数据集构建一个模型,根据新的输入数据预测相应的输出。
回归问题按照输入变量的个数可以分为一元回归和多元回归;
按照输入变量和输出变量之间关系的类型,可以分为线性回归和非线性回归。如果你和的线是一条直线,则被称为线性回归。非线性回归有常用的逻辑回归模型。
线性回归
一元线性回归最简单:y=ax+b(x为价格,y为销量,则该线性回归用来描述价格与销量的关系,一元代表输入只有一个维度-价格,求a和b的值)
多元回归,代表输入有多个维度。
可以用最小二乘法,梯度下降法求解线性预测函数的系数
逻辑回归(logistic )
逻辑回归的模型是一个非线性模型,它本质上又是一个线性回归模型,因为通过sigmoid映射函数(又称逻辑回归函数)关系,转换成线性回归问题来解决。
二、最小二乘法
最小二乘法适用于任意多维度的线性回归参数求解,它可求解出一组最优解,使得对于样本集中的每一个样本,用y=f(x1,x2,…xi,…xn)来预测样本,使得预测值与实际值的方差最小。
模型公式
θ和X都是列向量。
目标函数(损失函数)
根据最小二乘法定义,目标函数表示是预测值和真实值的差距。
直观的理解,为了避免正负抵消,是每个样本值与全体样本值的平均数之差的平方,和方差类似。如通过模型函数推导,较为复杂:
多维参数的数学推导
首先模型函数包含噪音项,根据中心极限定理,满足均值为0的高斯分布
有:
高斯分布表示如下:
通过极大似然MLE求得似然函数为所有样本的乘积
求log,将极大似然最大值转为log函数的最大值,
要使得最大似然最大,则需要最小二乘最小。有:
得出
当矩阵满秩时,求导后取极值点,令函数值为0,得出
也可以通过贝叶斯最大后验概率进行推导。
三、线性回归实例
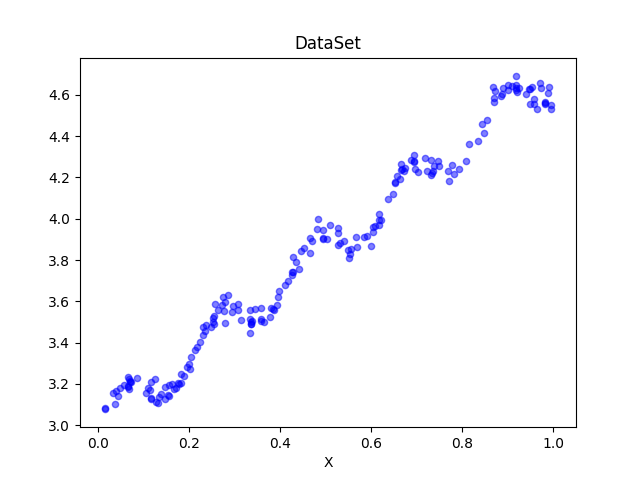
有数据如下,需要计算最优回归系数。
| x0-偏移量 | x1-x轴 | x2-y轴 |
|---|---|---|
| 1.000000 | 0.067732 | 3.176513 |
| 1.000000 | 0.427810 | 3.816464 |
| … | … | … |
| 1.000000 | 0.995731 | 4.550095 |
| 1.000000 | 0.738336 | 4.256571 |
| 1.000000 | 0.981083 | 4.560815 |
1 | import numpy as np |
1 | def standRegres(xArr, yArr): |
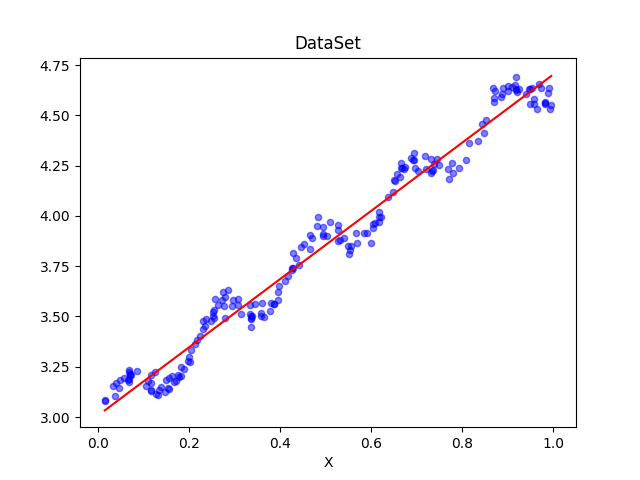
求解出的ws回归系数为,用函数表示为:y=3.00774324+1.69532264x
1 | [[3.00774324] |
四、局部加权线性回归
定义
局部加权线性回归(Locally Weighted Linear Regression,LWLR),是为了解决线性回归可能出现的欠拟合现象,在该方法中,我们给待预测点附近的每个点赋予一定的权重。形式如下:
对比之前的公式,区别在于多了W,来给每个点赋予权重。LWLR使用“核”(类似于向量机的核)来对附近的点赋予更高的权重,常用的核是高斯核,k被称为平滑参数,如下:
代码实现
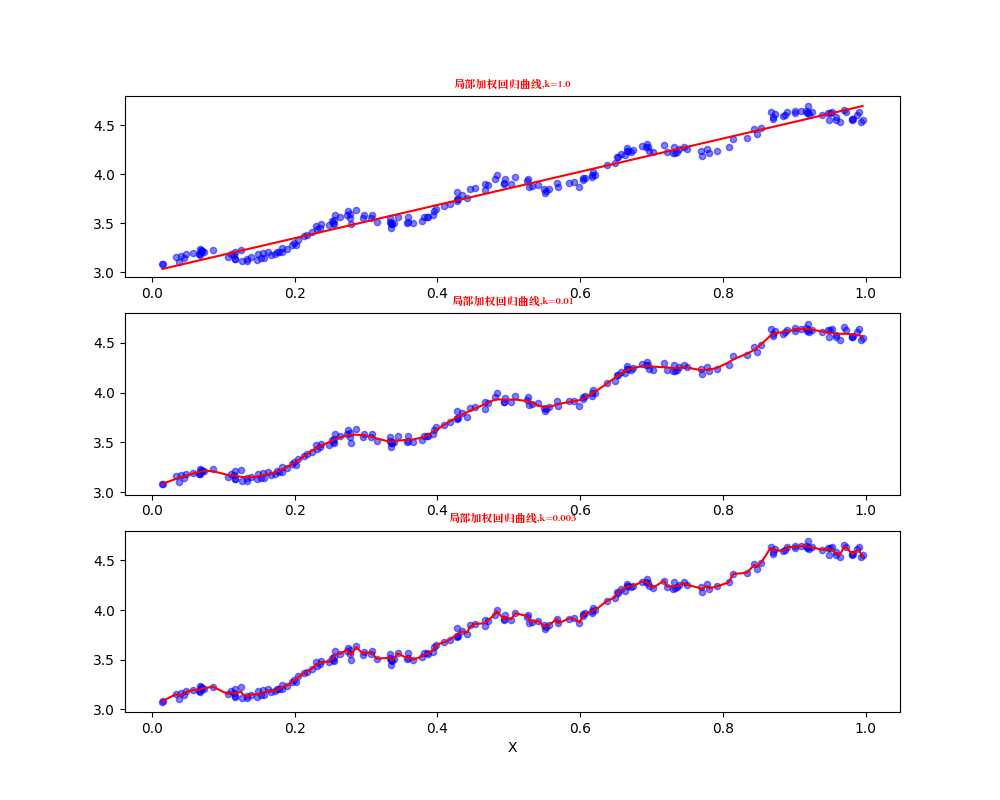
还是之前回归的数据,使用k=1,k=0.01,k=0.003进行局部加权线性回归,
1 | from matplotlib.font_manager import FontProperties |
可以看出当k越小(比如k=0.01),拟合效果越好。但是k=0.003时过小,导致考虑了太多噪声,进而导致了过拟合现象。
五、岭回归
上面提到,计算回归参数需要保证X^TX可逆(满秩)。那么如果数据的特征点比样本数还多,那么矩阵X肯定不是满秩矩阵,无法求逆,导致无法使用正常的线性回归。因此统计学家引入岭回归(ridge regression)的概念。
定义
岭回归就是在矩阵X^TX上加一个λI从而使得矩阵非奇异,进而能对X^TX + λI求逆。其中矩阵I是一个m×m的单位矩阵,对角线上元素全为1,其他元素全为0。而λ是一个用户定义的数值。回归系数的计算公式将变成:
这里通过引入λ来限制了所有θ之和,通过引入该惩罚项,能减少不重要的参数,这个技术在统计学中叫做缩减(shrinkage)
六、梯度上升和梯度下降
梯度上升(下降)法基于的思想是:要找到某函数的最大(小)值,最好的方法是沿着该函数的梯度方向探寻。函数f(x,y)的梯度由下面公式表示:
梯度是三维以上坐标系的概念,它在平面坐标系对应的概念是导数。二维平面中,导数代表线的倾斜方向和倾斜程度。三维空间中,梯度代表 面的倾斜方向和倾斜程度。线的倾斜方向只用正负表示,导数为正代表右斜,导数为负代表线左斜。面的倾斜方向是无穷的,由向量表示。
梯度上升和梯度下降,指的是你要计算的结果是函数的极大值还是极小值。计算极小值,就用梯度下降,计算极大值,就是梯度上升。
梯度上升
梯度上升的算法如下:
可以根据简化的二维平面y=-x^2函数来求最大值来理解,当x<0时导数为正,函数值在0时最大。
- 当取w<0时,导数为正,因此迭代后的w会往右侧(最大值所在的x=0)靠近。
- 当取w>0时,导数为负,因此迭代后的w会往左侧(最大值所在的x=0)靠近。
梯度下降
梯度下降的算法如下:
可以根据简化的二维平面y=x^2函数来求最小值来理解,当x>0时导数为正,函数值在0时最小。
- 当取w<0时,导数为负,因此迭代后的w会往右侧(最大值所在的x=0)靠近。
- 当取w>0时,导数为正,因此迭代后的w会往左侧(最大值所在的x=0)靠近。
当三维甚至多维时,w变成向量。
当矩阵不满秩时,可采用梯度下降算法来求局部最优解的方法。
七、Logistic回归和Sigmoid函数的分类
我们想要的函数应该是,能够接受所有的输入然后预测出类别。例如在两个类的情况下,分类函数能够输出0或1,这种函数称为“海威赛德阶跃函数”,然而这个函数的问题在于,该函数直接在跳跃点从0跳跃到1,这个瞬间的跳跃有点难处理。
幸好有个函数有类似的性质,并且在数据上更容易处理,这就是Sigmoid函数:
该函数的特性为:当x趋近于负无穷时,y趋近于0;当x趋近于正无穷时,y趋近于1;当x= 0时,y=0.5。
回归系数
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
什么是回归系数呢?可由下面公式得出
向量写法如下,其中向量x是分类器的输入数据,向量w就是回归系数。
损失函数的模型建立
根据z和g(z)公式,得出:
w是需要求解的参数向量,x是样本的数据集,函数实现了任意实数到[0,1]的映射,代表了输出为1的概率,当=0.6时,说明有60%的概率输出为1,40%的概率输出为0。即P(y=1|x,w)=和P(y=0|x,w)=
我们需要的是一个代价函数,使得样本要么是0,要么是1的概率更高,代表分类效果越好。因此构建出代价函数:
当y=1时,(1-y)为0;当y=0时,(1-y)为1,保证只保留两项中的一项。然后取对数简化:
对于某个数据集,由于样本之间相互独立,整个数据集的概率,是所有样本概率的乘积,我们也同样对数化(同时也由于很小的数相乘导致下溢出),每个样本的值越大,代表是0或者1的可能性越大,则分类越准确。问题变成求解如下代价函数J(w)的最大值问题。
其中,m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是w是多维向量,x(i)也是多维向量。
最佳回归系数的数学推导
求损失函数最大值,我们需要使用梯度上升算法。公式为:
现在开始求解J(w)对w的偏导:
三者都需要计算,较为复杂,最后会得到
最终得到梯度上升的迭代公式为:
八、逻辑回归分类示例
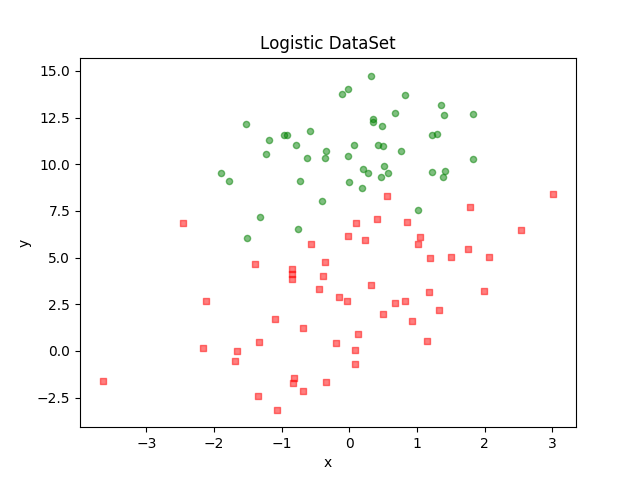
有数据如下,包含两维特征,训练逻辑回归分类。
| x轴 | y轴 | 分类标签 |
|---|---|---|
| -0.017612 | 14.053064 | 0 |
| -1.395634 | 4.662541 | 1 |
| … | … | … |
| 0.423363 | 11.054677 | 0 |
| 0.406704 | 7.067335 | 1 |
| 0.667394 | 12.741452 | 0 |
准备数据、可视化
1 | import numpy as np |
需要使用逻辑回归进行分类
梯度向上算法
1 | def sigmoid(inX): |
测试
1 | if __name__ == '__main__': |
结果为:
1 | [[ 4.12414349] |
结果可视化
1 | def plotBestFit(weights): |
